
Amazon Dynamo DB
Brief overview of the Amazon's Dynamo DB whitepaper with an interesting case study



Introduction
What is Dynamo ?
Key value storage system at Amazon
Provides an always on experience
Dynamo sacrifices consistency for Availability (CAP theory), under certain failure cases
Has versioning and application-assisted conflict resolution
At the scale of amazon’s infrastructure, small and large components fail continuously and the way persistent state is managed in the face of these failures drives the reliability and scalability of the software systems.
Reliability is a big factor for amazon as any outage has a good impact on their finances and customer trust, to ensure growth the platform should be scalable. Reliability and scalability depends on how the application state is managed
Amazon’s architecture has the following properties
Decentralised
Loosely coupled
Service-oriented architecture
At a scale of Amazon there is definitely a need for a storage system that is always available. Because at such a scale failure of machines and servers are common the failure shouldn’t be treated as a special case but a NORMAL case.
Speciality of Dynamo
High reliability
Tight control over the tradeoffs between availability, consistency and cost effective performance
There are many services on Amazon’s platform that only need primary-key access to a data store. For many services, such as those that provide best seller lists, shopping carts, customer preferences, session management, sales rank, and product catalog, the common pattern of using a relational database would lead to inefficiencies and limit scale and availability. Dynamo provides a simple primary-key only interface to meet the requirements of these applications.
Some techniques that dynamo uses
Data is partitioned and replicated using consistent hashing
consistency is facilitated by object versioning
The consistency among replicas during updates is maintained by a quorum-like technique and a decentralized replica synchronization protocol
a gossip based distributed failure detection and membership protocol
decentralized system with minimal need for manual administration
Storage nodes can be added and removed from Dynamo without requiring any manual partitioning or redistribution.
Dynamo was able to scale to extreme peak loads efficiently without any downtime during the busy holiday shopping season
🔥 The paper is trying to convey that an eventually-consistent storage system can be used in production with demanding applications. It also provides insight into the tuning of these techniques to meet the requirements of production systems with very strict performance demands
Note on stateless and stateful services
Stateless service - services which aggregate responses from other service
Stateful service - a service that generates its response by executing business logic on its state stored in persistent store
Traditionally (how it was done before) - state was stored in relational databases BUT for most common use cases this is not an ideal solution (why?)
Because most of the services only store and retrieve data by primary key and DO NOT require the complex querying and management functionality of an RDBMS. (Better have it than not need it?) The excess functionality requires better hardware (meaning more cost) and skilled workforce to manage
HENCE using RDBMS is not an efficient solution.
ALSO, available replication technologies are very limited and choose consistency over availability.
Dynamo solves for the above discussed problem.
Dynamo has a simple key/value interface, is highly available with a clearly defined consistency window, is efficient in its resource usage, and has a simple scale out scheme to address growth in data set size or request rates. Each service that uses Dynamo runs its own Dynamo instances.
System Assumptions and Requirements
Query Model :
Simple read and write to a data item uniquely identified with a key.
State is stored as binary objects (blobs)
No operation span multiple data items, NO NEED for relational schema
Dynamo targets application that to store objects that are relatively small (less than 1 MB)
ACID Properties :
Observation : data store that guarantees ACID properties have POOR availability.
Dynamo targets applications that operate with weaker consistency, if this means the system is more available
Dynamo DOES’NT provide any isolation guarantees and permit only single key update
Efficiency :
Should run on commodity hardware
Amazon has a tight latency requirements, Dynamo is expected to meet these requirements
Services must be able to configure Dynamo such that they consistently achieve their latency and throughput requirements
The tradeoffs are in performance, cost efficiency, availability, and durability guarantees
Other Assumptions: Dynamo is used only by Amazon’s internal services. Its operation environment is assumed to be non-hostile and there are no security related requirements such as authentication and authorization. Moreover, since each service uses its distinct instance of Dynamo, its initial design targets a scale of up to hundreds of storage hosts
⚠️ Before we dive deep into the architecture and implementation it is good to have an understanding of consistent hashing you can check the video by Gaurav Sen here
System Architecture
Till now we should be clear with why there is a need for Amazon Dynamo to exist in the ecosystem, its feature to be highly available has been of use to many industries. We are going to talk about a very good case study of how Dynamo helped Zomato to scale up. Lets dive into the system architecture straight up
Introduction
The architecture of a storage system that needs to operate in a production setting is complex. In addition to persistence it has to manage many other jobs like load balancing, membership and failure detection, failure recovery, replica synchronization, overload handling, state transfer, concurrency and job scheduling, request marshalling, request routing, system monitoring and alarming, and configuration management. But discussing all of this in detail is a bit out of scope for this blog (let us know if we should get other blogs out on storage system architecture details). But for now we will simply come to the point of Amazon Dynamo.
Dynamo has following techniques to discuss: partitioning, replication, versioning, membership, failure handling and scaling. Let us start with the basic system interface that comes on the top layer of the Dynamo Architecture
System Interface
Dynamo simply provides two methods get(key) and put(key, context, object). The get method locates the object replicas associated with the key in the storage system and returns a single object or a list of objects with conflicting versions along with a context.
The put(key, context, object) operation determines where the replicas of the object should be placed based on the associated key, and writes the replicas to disk.
Context is generated by encoding the metadata about the object to be stored which makes it opaque to the client and also includes information like version of the object. The context is kept with the object so that the Dynamo can validate the object.
Dynamo used MD5 to hash the key which generates a 128 bit identifier used to determine the storage nodes which will be responsible for serving the key when asked.
Partition Algorithm
Dynamo ensures to scale incrementally which introduces a need to partition the data dynamically over the set of nodes. To do this they follow a method similar to Consistent Hashing. Here the rule is simple, we have a circular ring and the storage hosts are assigned positions on this ring uniformly with the help of a hash function remainder with the ring length. Each data item identified by a key is assigned to a host by hashing the data item’s key to yield its position on the ring, and then walking the ring clockwise to find the first node with a position larger than the item’s position.
This classic algorithm introduces challenges, as the hosts are distributed randomly the load distribution might get non uniform, and in case of failure of server host the load will increase on the next host in the ring and hence will make the system unstable. So to resolve this Dynamo uses the concept of Virtual Hosts, where there would be lets say N number of hash functions which will give one server N positions within the ring limit, and hence this way they fine tune the partition scheme of Dynamo.
Lets say if the node is compromised, instead of sending its load to the next available node, the load is evenly distributed across all the other hosts, and when a new node comes it roughly gets back the equivalent amount of load onto it.
Replication
Now that we discussed about the partition algorithm that Dynamo Uses to partition the data dynamically, next thing that we should focus on is the Replication. It is important because such important data if stored on just one host with no copies will not make Dynamo highly available (what if that host gets corrupted). To ensure this Dynamo uses the concept similar to the ring where once the data is assigned to a host it replicated that data to next N-1 hosts in a clockwise manner (N is the number of copies of one data that needs to be created). The node that replicated this to next N-1 is called the coordinator node in the ring for that key. The coordinator is in charge of the replication of the data items that fall within its range. This results in a system where each node is responsible for the region of the ring between it and its Nth predecessor.
The list of nodes that is responsible for storing a particular key is called the preference list. The system is designed in such way later such that every node in the system can determine which nodes should be in this list for any particular key. The preference list contains more than N nodes to account for node failures.
This still creates one problem that might hamper the availability i.e., blindly copying the replicas to the next N-1 hosts will lead to a condition multiple vnodes from the same physical node being selected for replication. To avoid this, Dynamo constructs a preference list by skipping vnodes that map to the same physical node. This ensures that the data is replicated across distinct physical nodes, enhancing the system's fault tolerance and reliability.
Data Versioning
Lets assume you are adding the brand new product to the cart it apparently internally calls the dynamo put routine (discussed earlier). It will then use the partition algorithm and the replication mechanisms discussed above to replicate the data to multiple hosts. But assuming due to some network partition or server timeout issue, the data doesnt get replicated to all the nodes at a time and apparently you try to check you cart and you might receive older version of your cart from some different server which will hamper the eventual consistency that Dynamo is trying to provide.
They have created a very strong and interesting system to handle this scenario by versioning the objects before putting them into the Dynamo. Dynamo treats the result of each modification as a new and immutable version of the data. It allows for multiple versions of an object to be present in the system at the same time. Most of the time, new versions subsume the previous version(s), and the system itself can determine the authoritative version (syntactic reconciliation). However, version branching may happen, in the presence of failures combined with concurrent updates, resulting in conflicting versions of an object. This created a new P0 for them to consider while designing Dynamo where they introduce the vector clocks.
Vector clock is nothing but a pair of (host, counter). It is associated with every version of the object that is being pushed. One can determine if there is a conflict by examining the vector clocks of two different versions. If the counter of first clock is ≤ number of nodes in the second clock then we can assume that one is ancestor of second and we can forget that. But if it is not the case then its a conflict and reconciliation is needed.
When the client is updating the object it should specify in the context (discussed in system interface) that which version it is updating. Let us look into a short example of vector clocks.
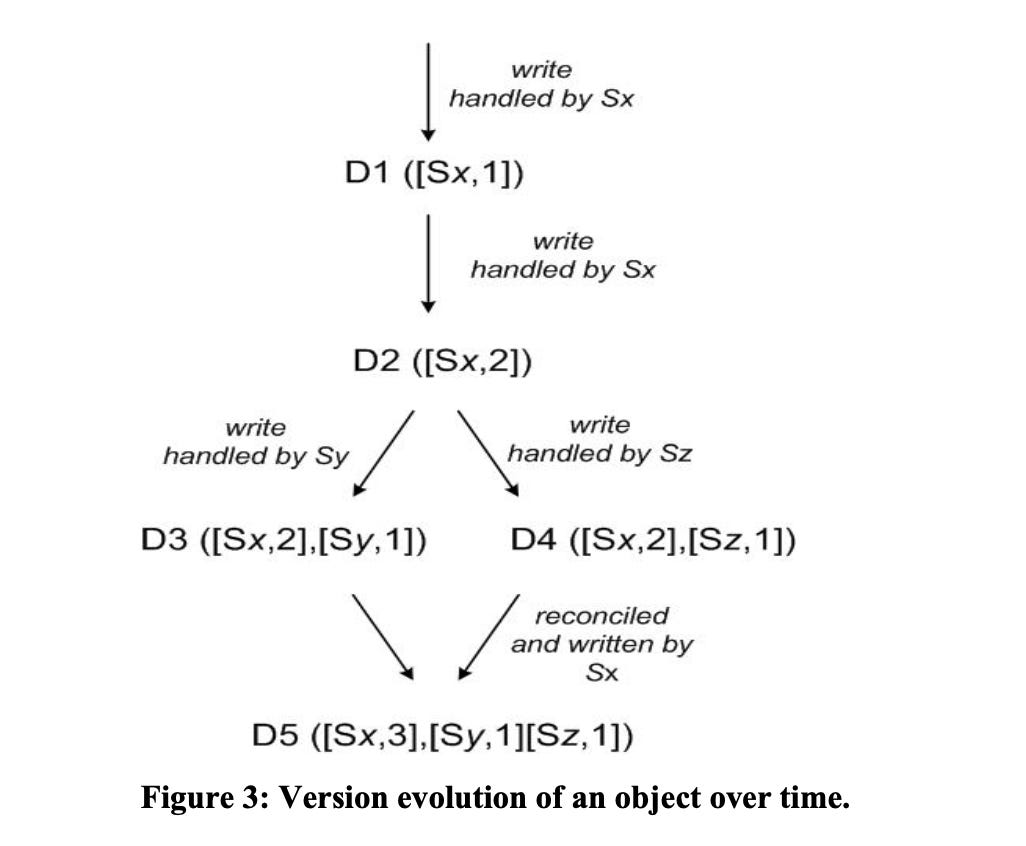
Let us say I am going to buy Alexa as it is a payday sale :), so I add it in my cart and from Dynamo’s perspective it uses a server Sx and it created a new data vector clock D1 storing [Sx, 1]. Then you see that you have a coupon to apply and buying two item gets cheaper so u update the item count which is handled by the same server Sx and the data clock is now [Sx, 2]. After some time you see that you dont want 2 you are okay with just 1 alexa so you again update the object but this time Sy a new server handles your request and it creates its own vector clock say [Sx, 2][Sy, 1], and again after some time you update the model of alexa and this time it is handled by some another server say Sz and its vector clock is [Sx, 2][Sz, 1]. There are changes in D3 and D4 that are not reflected in each other. Both versions of the data must be kept and presented to a client (upon a read) for semantic reconciliation.
Now when I try to check my cart later for a price then it will try to provide me the data for the get call from D3 and D4. Through context it gets to know the following state of clocks [Sx, 2][Sy, 1][Sz, 1], now when the client will reconcile the conflicts and if lets say Sx is going to reconcile then it will update the state of clock to [Sx, 3][Sy, 1][Sz, 1]. So even if the network partition was happening still my alexa is updated and available for me in the cart, and hence I finally proceed to buy it :)
One problem might come that due to multiple update during a prolong issue in server may lead to multiple diverging versions of the object and it will increase the size of the vector clock, which will make system unstable. So to meet this they have decided to implement a vector clock truncation scheme where they set a limit of lets say 10 and store with timestamp. So when the size reaches the threshold the oldest item is removed. But on production they have actually not experienced this problem till now because such a long network failure or system downtime is not desirable. Hence they have still now investigated this much.
Hence this shows how while using amazon services you never loose your updates even if system is experiencing issues and it is always available :)
Execution of get and put operations
Any node can receive get and put operations. The following section discusses the execution of get and put in an ideal scenario i.e no failure cases
The client has 2 strategies to select a node to perform read or write
Client can use a partition-aware client library that routes requests directly to the appropriate coordinator nodes
Advantage is that this approach offers lower latency because it skips a potential forwarding step
Client can use a partition-aware client library that routes requests directly to the appropriate coordinator nodes
Advantage is that this approach offers lower latency because it skips a potential forwarding step
The node that receives the read/write request is called the coordinator. Most probably it will be the first node in the N node preference list. In the case of using a load balancer to access a particular key (to read from or write to) the request might hit any random node in the ring, it is important to note here that in this scene the random node WILL NOT coordinate to the right node (for access) if it is not in the top N of the preference list, instead it will redirect the request to the first in the preference list
Only the first N healthy nodes are involved in read and write operations thus skipping the nodes which are down or have failed due to some reason. When all nodes are healthy, the top N nodes in a key’s preference list are accessed. When there are node failures or network partitions, nodes that are lower ranked in the preference list are accessed.
Consistency protocol
This section is very important and this is what makes dynamo highly configureable. To maintain consistency across multiple nodes Dynamo uses a consistency protocol which has 2 dials R and W. The R dial controls the minimum number of nodes that must return SUCCESS for a successful read and the W dial controls the minimum number of nodes that must return SUCCESS for a successful write.
If we set R + W > N we get a quorum-like system. The latency of such a system is found by looking at the slowest of the R (or W) nodes, to achieve a better latency a common practice is to keep R and W less than N.
Let us see 2 example scenario to understand
Scenario 1 : Node receives a put() request
Actions :
coordinator (node that receives put req) starts vector clock for new version and writes locally
coordinator then sends new version to the N-highest ranked reachable nodes
if W-1 nodes respond YES then the write is success
Scenario 2 : Node receives a get() request
Actions :
coordinator (node that receives put req) req all versions of the key from N nodes
coordinator waits for responses, If it receives more than R responses it returns to the client
if coordinator gets different versions it returns all the versions that it finds causally unrelated to client
The different versions are then brought together and the new version superseding the current version is written back
Handling Failures: Hinted Handoff
Dynamo uses sloppy quorum
All read and write operations are performed on the first N healthy nodes from the preference list (may not be first N nodes while walking the consistent hashing ring)
In this example say N (number of healthy nodes) = 3. If node A is temporarily down during a write operation then a replica that would normally lived in A will now be sent to node D
This is done to maintain the desired availability and durability guarantees. The replica sent to D will have a hint in its metadata that suggests which node was the intended recipient of the replica (in this case A).
Nodes that receive hinted replicas will keep them in a separate local database that is scanned periodically. Upon detecting that A has recovered, D will attempt to deliver the replica to A. Once the transfer succeeds, D may delete the object from its local store without decreasing the total number of replicas in the system.
Applications that need the highest level of availability can set W to 1, which ensures that a write is accepted as long as a single node in the system has durably written the key it to its local store. Thus, the write request is only rejected if all nodes in the system are unavailable. However, in practice, most Amazon services in production set a higher W to meet the desired level of durability
(Real world use case consideration - What happens when data centre dies due to natural causes)
Dynamo is configured such that each object is replicated across multiple data centers. In essence, the preference list of a key is constructed such that the storage nodes are spread across multiple data centers. These datacenters are connected through high speed network links. This scheme of replicating across multiple datacenters allows us to handle entire data center failures without a data outage.
Handling permanent failures : Replica synchronisation
There are scenarios under which hinted replicas become unavailable before they can be returned to the original replica node. To handle this and other threats to durability, Dynamo implements an anti-entropy (replica synchronization) protocol to keep the replicas synchronized.
To detect the inconsistencies between replicas faster and to minimize the amount of transferred data, Dynamo uses Merkle trees
Why? Merkle trees minimize the amount of data that needs to be transferred for synchronization and reduce the number of disk reads performed during the anti-entropy process.
Each node maintains a separate Merkle tree for each key range (the set of keys covered by a virtual node) it hosts.
In this scheme, two nodes exchange the root of the Merkle tree corresponding to the key ranges that they host in common. Subsequently, using the tree traversal scheme described above the nodes determine if they have any differences and perform the appropriate synchronization action.
The disadvantage with this scheme is that many key ranges change when a node joins or leaves the system thereby requiring the tree(s) to be recalculated.
Membership and Failure Detection
Ring Membership
In Amazon’s use case node failures are often not permanent (i.e they are transient) but they can last for extended intervals.
A node outage rarely signifies a permanent departure and therefore should not result in rebalancing of the partition assignment or repair of the unreachable replicas.
Manual error could result in the unintentional startup of new Dynamo nodes
For these reasons, it was deemed appropriate to use an explicit mechanism to initiate the addition and removal of nodes from a Dynamo ring.
An admin uses some interface to connect to a node and tell the system that a new node is joining or an existing node is exiting. The coordinator writes this change and time to the persistent storage. These entry and exit of nodes form a history as nodes can join and leave the system multiple times. The nodes talk to each other using a gossip based-protocol and the system eventually becomes consistent from the view of membership change histories.
The process that happens on entry and exit of new/existing node is discussed in the next section
External Discovery
Imagine a scene where the admin asks Node A to be a part of the system and Node B to be a part of the system, now each of the individual nodes know that they are a part of the system but are unaware of the other node in the system. To prevent logical partitions some nodes play the role of seeds .
So what are seeds ?
Seeds are nodes that are discovered via an external mechanism and are known to all nodes.
Because all nodes eventually reconcile their membership with a seed, logical partitions are highly unlikely.
Seeds can be obtained either from static configuration or from a configuration service.
Typically seeds are fully functional nodes in the Dynamo ring.
Failure Detection
To avoid unnecessary attempts of reaching an unreachable node for get or put operation or to know if transferring partitions and hinted replicas were successful failure detection is important to the Dynamo system
For the purpose of avoiding failed attempts at communication, a purely local notion of failure detection is entirely sufficient:
Node A may consider node B failed if node B does not respond to node A’s messages (even if B is responsive to node C's messages).
In the presence of a steady rate of client requests generating internode communication in the Dynamo ring, a node A quickly discovers that a node B is unresponsive when B fails to respond to a message; Node A then uses alternate nodes to service requests that map to B's partitions; A periodically retries B to check for the latter's recovery.
In the absence of client requests to drive traffic between two nodes, neither node really needs to know whether the other is reachable and responsive. Decentralized failure detection protocols use a simple gossip-style protocol that enable each node in the system to learn about the arrival (or departure) of other nodes.
Early designs of Dynamo used a decentralized failure detector to maintain a globally consistent view of failure state. Later it was determined that the explicit node join and leave methods obviates the need for a global view of failure state.
WHY? This is because nodes are notified of permanent node additions and removals by the explicit node join and leave methods and temporary node failures are detected by the individual nodes when they fail to communicate with others (while forwarding requests).
Adding and Removing Storage Nodes
On adding a new Node X to the system,
X gets assigned a number of tokens that are randomly scattered across the ring.
Now X will get assigned a set of key ranges, for every key range there may be a some nodes that were previously incharge for those key ranges
Because of reallocation of these key ranges the previous nodes are no longer incharge and don’t have to handle these keys so they transfer some of these keys to X
Example
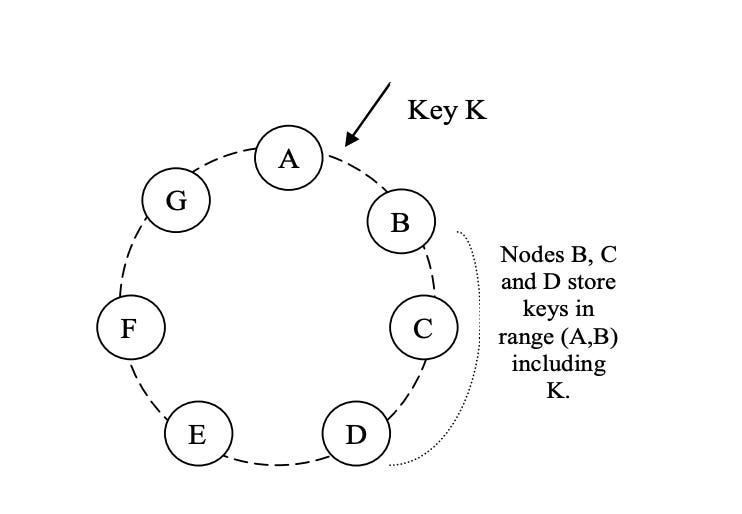
X is added between A and B
X is in-charge of key ranges (F, G], (G, A] and (A, X]
nodes B, C and D no longer have to store the keys in these respective ranges.
nodes B, C, and D will offer to and upon confirmation from X transfer the appropriate set of keys.
⚠️ On removing a node the reallocation will happen in the exact reverse process
Operational experience has shown that this approach distributes the load of key distribution uniformly across the storage nodes, which is important to meet the latency requirements and to ensure fast bootstrapping.
Finally, by adding a confirmation round between the source and the destination, it is made sure that the destination node does not receive any duplicate transfers for a given key range.
Implementation
Each storage node has 3 main SOFTWARE components
Request coordination
Membership and failure detection
Local persistence engine
(All of them are implemented in JAVA)
The local persistence component allows for different storage engines to be plugged in. The main REASON for designing a pluggable storage component is to choose the best suited storage engine for the application based on the object size distribution.
The request coordination component is built on top of an event-driven messaging substrate where the message processing pipeline is split into multiple stages. All communications are implemented using Java NIO channels. The coordinator executes the read and write requests on behalf of clients by collecting data from one or more nodes(reads) or storing data at one or more nodes.
Each client request that reaches a node creates a state machine on that node. The state machine has all the logic for identifying the nodes responsible for a key, sending the req, waiting for res, potentially doing retries, processing the replies and packing the res to the client.
Each state machine handles exactly one client request
Example : A read operation implements the following state machine
(i) send read requests to the nodes,
(ii) wait for minimum number of required responses,
(iii) if too few replies were received within a given time bound, fail the request,
(iv) otherwise gather all the data versions and determine the ones to be returned and
(v) if versioning is enabled, perform syntactic reconciliation and generate an opaque write context that contains the vector clock that subsumes all the remaining versions. For the sake of brevity the failure handling and retry states are left out.
After the read response has been returned to the caller the state machine waits for a small period of time to receive any outstanding responses. If stale versions were returned in any of the responses, the coordinator updates those nodes with the latest version. This process is called read repair because it repairs replicas that have missed a recent update at an opportunistic time and relieves the anti-entropy protocol from having to do it
As noted earlier, write requests are coordinated by one of the top N nodes in the preference list. Although it is desirable always to have the first node among the top N to coordinate the writes thereby serializing all writes at a single location, this approach has led to uneven load distribution resulting in SLA violations. This is because the request load is not uniformly distributed across objects.
To counter this, any of the top N nodes in the preference list is allowed to coordinate the writes. In particular, since each write usually follows a read operation, the coordinator for a write is chosen to be the node that replied fastest to the previous read operation which is stored in the context information of the request
This optimization enables us to pick the node that has the data that was read by the preceding read operation thereby increasing the chances of getting “read-your-writes” consistency. It also reduces variability in the performance of the request handling which improves the performance at the 99.9 percentile.
Real world use-case by Zomato :
Zomato is a food ordering and delivery platform that experiences heavy traffic during peak meal hours. Zomato's billing platform is responsible for managing post-order processes, maintaining ledgers and taking care of the payouts. Additionally, it needs to handle the load of delivering payouts to delivery and restaurant partners at scale. It thus, requires a low latency, cheap and reliable database. Technically, the platform uses Kafka for asynchronous messaging between its microservices. The platform used TIDB to manage its online transaction processing which gave it the scalability of NoSQL databases along with ACID properties of a SQL database. The team was fairly familiar with MySQL and TiDB was horizontally scalable, hence the decision to use it. After experiencing an increasing load, the team faced some challenges with TiDB. Changing schemas impacted the query performance, especially in data intensive tables. The distributed nature while being beneficial in the beginning, became complicated when compared to a central database. The cluster size was being increased manually whenever heavy traffic was anticipated.
The Zomato TiDB cluster was self managed (managed by the Zomato team), the team had to handle labour intensive tasks like synchronising replicas, monitoring storage, adding extra nodes, and backup management. As the data grew, so did the backups leading to slower processing time. With all these challenges, there was a need to find a better alternative.
So out of a lot of options available, why go with DynamoDB? DynamoDB is server-less, NoSQL based DB with a pay for only what you use notion. DynamoDB performs consistently and reliably, even at scale. When related data is kept together, there is no need for heavy query optimisations. DynamoDB supports auto scaling, backing the application's need during peak hours while being cost effective. It eliminates all the manual intervention that was required with TiDB. Aware of the challenges and issues, the Zomato team re-designed their data storage layer. The relational schema was changed to a unified DynamoDB table using an adjacency list design pattern. This decision, reduced cost and time for operation since all related data was stored together eliminating the need for multiple or complex queries. Improper schema definition or improper choice of partition key can cause hot partitions. The team solved this by choosing the partition key with composite attributes, allowing data distribution across multiple partitions. To query data, they used secondary indices, this facilitated querying the data across many-to-many relationships. To ensure an even distribution of read and write operations across the many partitions, a division number was introduced. The team used a phased approach to handle this migration and the results of this migration were fascinating.
There was an average decrease of 90% in the response time for microservices and response time was now consistent. The migration successfully eliminated the performance bottleneck of the previous database and increased the throughput of the microservice. Additionally because of auto-scaling, the costs were brought down by 50%.
Resources :
The paper was interesting and helped us pick up new patterns like consistent hashing. The zomato blog especially helped us understand the real world use-case and implementation of the concepts that the paper discusses, to go along with it here are a few other resources
Paper : https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
Blog on how zomato used Dynamo DB : https://blog.zomato.com/switching-from-tidb-to-dynamodb
Dynamo DB on AWS : https://aws.amazon.com/dynamodb/resources/
Video on consistent hashing : https://www.youtube.com/watch?v=zaRkONvyGr8