
Flash Attention
Supercharging Transformers with Lightning-Fast Memory Efficiency

Transformers and Attention
With so much talk and “attention” (pun intended, I am sorry it was right there) around AI, I am 100% sure that all of us has some vague idea of what transformers are, just so that we are all in the same page
💡Transformers are a type of deep learning model designed to process sequential data (like text, images, audio, etc.) efficiently.
Now the word attention might start making some sense from this, thoughts like is it related to the context the model has at any given time might be popping up, again so that we are all in the same page
💡In simple words attention is a mechanism that helps models focus on important parts of input.
Before attention, models like RNNs processed words one by one, making it hard to remember important information from far back in the input.
Example: Translating the sentence:
"The cat sat on the mat because it was warm."
A simple model might struggle to connect "it" with "the mat", especially in long sentences.
Attention helps by focusing on the most relevant words while making predictions.
Self attention
Self-attention is the core operation of Transformers that allows each token in a sequence to weigh the importance of other tokens before generating an output representation
Given a sequence of token embeddings, self-attention computes attention scores using three matrices:
Query (Q) – Represents the token asking for information.
Key (K) – Represents the token providing the information.
Value (V) – Represents the actual information being passed.
The attention mechanism works as follows:
Compute attention scores (S) :
$$ S = QK^T $$
This results in an N×N matrix, where N is the sequence length.
Apply softmax normalization:
$$ P=softmax(S) $$
Compute weighted sum of values:
$$ O = PV $$
Now lets see the complexity of this process
Computational Complexity:
$QK^T$ is a matrix multiplication of size $N × d$ and $d ×N$ leading to
The softmax operation and multiplication with V also contribute to $O(N^2d)$, making it quadratic in $N$.
Memory Complexity:
The attention matrix S is $N×N$, meaning we need memory just to store it.
As a result, when processing long sequences (e.g.,N=16K), both computation and memory requirements become impractical
And now we have finally come to the problem statement HOW DO I MAKE THIS FASTER
💡An important question is whether making attention faster and more memory efficient can help Transformer models address their runtime and memory challenges for long sequences.
Problems with Standard Self-Attention
Quadratic Complexity:
Standard self-attention has O(N^2 d) compute and O(N^2) memory requirements.
This makes it slow and memory-hungry, especially for long sequences (e.g., 16K+ tokens).
Memory Bottleneck (IO-bound computation):
GPUs have a memory hierarchy:
Fast but small SRAM (~20MB, 19TB/s bandwidth)
Slower but large HBM (~40GB, 1.5TB/s bandwidth)
Standard attention loads/stores large matrices (N×N) in slow HBM, causing huge IO overheads.
Existing Approximate Attention Methods Don’t Achieve Real Speedups:
Sparse, low-rank, and kernel-based methods reduce FLOPs but still suffer from memory access bottlenecks.
As a result, they don’t show significant wall-clock speedup in real training scenarios.
Other attempts to solve
Below is a summary of some of the approaches that are there other than Flash Attention that attempt to solve the same problem

Enter Flash Attention
FlashAttention is a memory-efficient, IO-aware algorithm designed to speed up self-attention by optimizing how data moves between GPU memory (HBM) and fast on-chip memory (SRAM).
Instead of changing the attention mechanism itself, FlashAttention reorganizes computation to reduce slow memory accesses.
Main goal: Avoid reading and writing the full attention matrix to/from slow GPU memory (HBM).
Approach:
1️⃣ Softmax Reduction Without Full Input Access
Standard attention requires full matrix storage to compute softmax.
Solution: Use tiling (split input into blocks) and process it incrementally.
2️⃣ Avoid Storing Large Intermediate Matrices for Backpropagation
Standard attention stores the full attention matrix for the backward pass.
Solution: Store only softmax normalization factors and recompute attention on-chip during backpropagation.
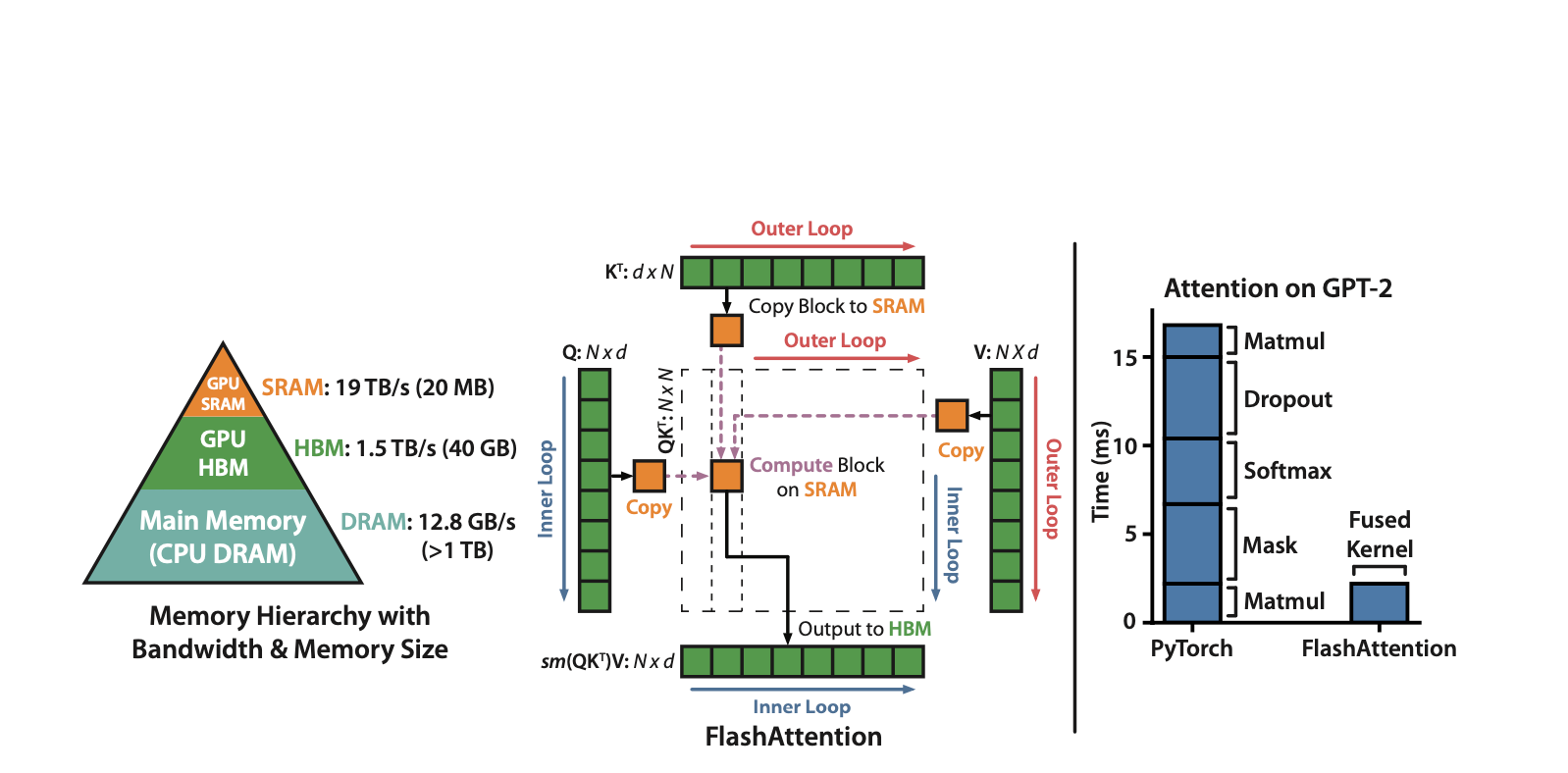
Result: Faster training, lower memory usage, and better scalability for long sequences
Performance Benefits:
Runs up to 7.6× faster (e.g., on GPT-2).
Uses less memory → Memory grows linearly with sequence length instead of quadratically.
Massively reduces HBM accesses, improving efficiency.
IO Complexity Analysis:
FlashAttention requires O(N^2 d^2 M^{-1}) HBM accesses, where:
N = Sequence length
d = Head dimension
M = Size of on-chip SRAM
Compared to standard attention (Ω(Nd + N^2)), FlashAttention reduces HBM accesses by up to 9×.
💡The main idea is that we split the inputs Q,K,V into blocks, load them from slow HBM to fast SRAM, then compute the attention output with respect to those blocks. By scaling the output of each block by the right normalization factor before adding them up, we get the correct result at the end.
The algorithm

Block-Sparse FlashAttention:
Block-Sparse FlashAttention is an extension of FlashAttention that improves efficiency by computing attention only for selected blocks of tokens, rather than for every token pair. This makes it even faster while reducing memory usage further.
Key Idea
Instead of computing the full N×NN \times NN×N attention matrix, we use a predefined block sparsity pattern that determines which parts of the matrix to compute.
This allows FlashAttention to skip unnecessary computations, improving speed and efficiency.
How Doest It Work?
Define a Block-Sparse Mask
The attention matrix is divided into blocks (size Br×Bc).
A mask matrix M is used to indicate which blocks should be computed.
MM
Compute Attention Only for Non-Zero Blocks
Blocks that are masked out are skipped, reducing computations.
The remaining blocks are processed using FlashAttention’s optimized tiling approach.
Lower IO Complexity
The number of HBM accesses reduces to O(N^2 d^2 M^{-1} s), where s is the sparsity ratio (fraction of non-zero blocks).
This makes it even more memory-efficient compared to dense FlashAttention.
Performance Benefits
2-4× faster than standard FlashAttention
Scales to extremely long sequences (up to 64K tokens!)
Works well for tasks where full attention isn’t necessary (e.g., vision, long-text modeling).
Limitations of FlashAttention
Requires Custom CUDA Kernels
FlashAttention is hardware-specific and needs low-level CUDA programming for optimization.
This makes it harder to implement and maintain compared to standard PyTorch/TensorFlow operations.
Limited to GPUs with Sufficient SRAM
The algorithm relies on on-chip SRAM for tiling, so performance gains depend on the GPU architecture.
Older or low-end GPUs with small SRAM may not benefit as much.
Increased FLOPs Due to Recomputation
While memory savings are significant, FlashAttention trades extra computation (FLOPs) for reduced memory access.
This may slightly increase power consumption in some cases.
Not a Drop-in Replacement for All Models
Works best for long-sequence tasks; short sequences may not see major speedups.
Requires modifications to existing Transformer implementations to integrate FlashAttention.
Resources :
The paper : https://arxiv.org/pdf/2205.14135
A basic explanation of the algorithm from the legend Andrej Karpathy himself :
3Blue1Brown Video on Attention :
Short summary : https://huggingface.co/docs/text-generation-inference/en/conceptual/flash_attention
Very interesting blog : https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad
Stanford Lecture :