

Abstract
What is MapReduce ?
It is just an approach (programming model) for processing and generating large data sets
OR Simplified Data Processing on large datasets
Users tell us a map function that processes key/value pairs
We use this to generate a set of intermediate key/value pairs
And a reduce function
We use this to merge all intermediate values which have the same key
How does it help ?
A lot of real world problems are expressible in this model
Programs written in this functional style are automatically parallelised and executed on large cluster of normal (commodity) machines
The run-time system takes care of details like splitting data, scheduling program execution and handling machine failures across your set of computers
This enables coders like us (who are just beginning their journey into distributed systems) to use the resources of a large distributed system
The papers implementation in highly scalable, just to set context on how its used at scale a normal map reduce computation crunches many TBs of data on thousands of machines
Introduction
Everyone knows how much data google has (its probably more than the number you have in your head). But with more data comes more responsibility 😜.
The responsibility to process such huge data over a few thousands of machines raises concerns like “How to parallelise the computation” / “How to distribute data” / “ How to handle failures” etc
To avoid solving this problem over and over again Google came up with an abstraction that lets coders express simple computation that they have to do and hide all the mess that happens underneath
The abstraction is inspired by Map Reduce present in Lisp (and other languages), let us understand how it works in lisp with 2 examples (for more context)
map f list[l1, l2, l3,...]here f is normally a unary operator so an example can bemap cube [1,2,3]→[1,8,27]
reduce f list[l1, l2, l3,....]here f is a binary operator, an example can bereduce + list[1, 2, 3]→6
This kind of pattern is present in many other languages as well
Re-iterating what google aims to achieve with this approach
🔑 “Our use of a functional model with user-specified map and reduce operations allows us to parallelize large computations easily and to use re-execution as the primary mechanism for fault tolerance.
The major contributions of this work are a simple and powerful interface that enables automatic parallelization and distribution of large-scale computations, combined with an implementation of this interface that achieves high performance on large clusters of commodity PCs.”
Programming Model
Map (written by user) - takes an input pair and gives a set of intermediary key/value pairs
Reduce (written by user) - takes an intermediary key I and set of values for that key and merges these values to a smaller set of value
Normally just 0 or 1 output value is produced per Reduce operation
The intermediary values are given to reduce function via an iterator, this enables handling of lists that are too large to fit in memory
Example
Problem statement : Count number of occurrences of each word in a large collection of documents
Pseudo code :
// emits 1 for every word it has
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
//counts all of the occurences of the word
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
⚠️ The complete c++ code is available for this at the end of the paper
Types
map (k1, v1) → list(k2,v2)reduce (k2, list(v2)) → list(v2)
notice that the input keys and values are drawn from a different domain than the output keys and values.
More examples of problems being expressed in MapReduce computations
Distributed Grep :
map - emits line if pattern is matched
reduce - copies the data to the output
Count of URL Access frequency :
map - processes logs of web page req and outputs and returns
<URL,1>return - adds all values for the same
URLand emits<URL, total_count>
Reverse Web-Link Graph :
map - emits a value like
<target, source>reduce - collects and returns a value like
<target, list(sources)>
💡 Try some of these examples on your own, there can be multiple answers but you can cross check them from page 3 of the paper
Inverted Index
Term-Vector per host (A term vector summarizes the most important words that occur in a document or a set of documents as a list of hword, frequencyi pairs)
Implementation
There are many possible implementations of MapReduce, the correct way depends on the environment
one implementation may be suitable for a small shared-memory machine, another for a large NUMA multi-processor, and yet another for an even larger collection of networked machines.
The below implementation takes into consideration Google’s environment
Google’s environment :
Machines - dual-processor x86 processors, running linux with 2-4 GB of memory per machine
Commodity networking hardware - 100 mbps or 1 gbps at machine level
A cluster has 100s/1000s of machines
Storage is provided by inexpensive IDE disks attached directly to individual machine.
User submits jobs to scheduling system. Each job consists of a set of tasks, and is mapped by the scheduler to a set of available machines within a cluster
Execution overview
Map calls are distributed over multiple machines by automatically partitioning the input data into M splits
Input splits can be processed independently
Reduce splits are distributed by partitioning the intermediate key space into R pieces using a partitioning function (eg :
hash(key) mod R)R and partition function are given by user
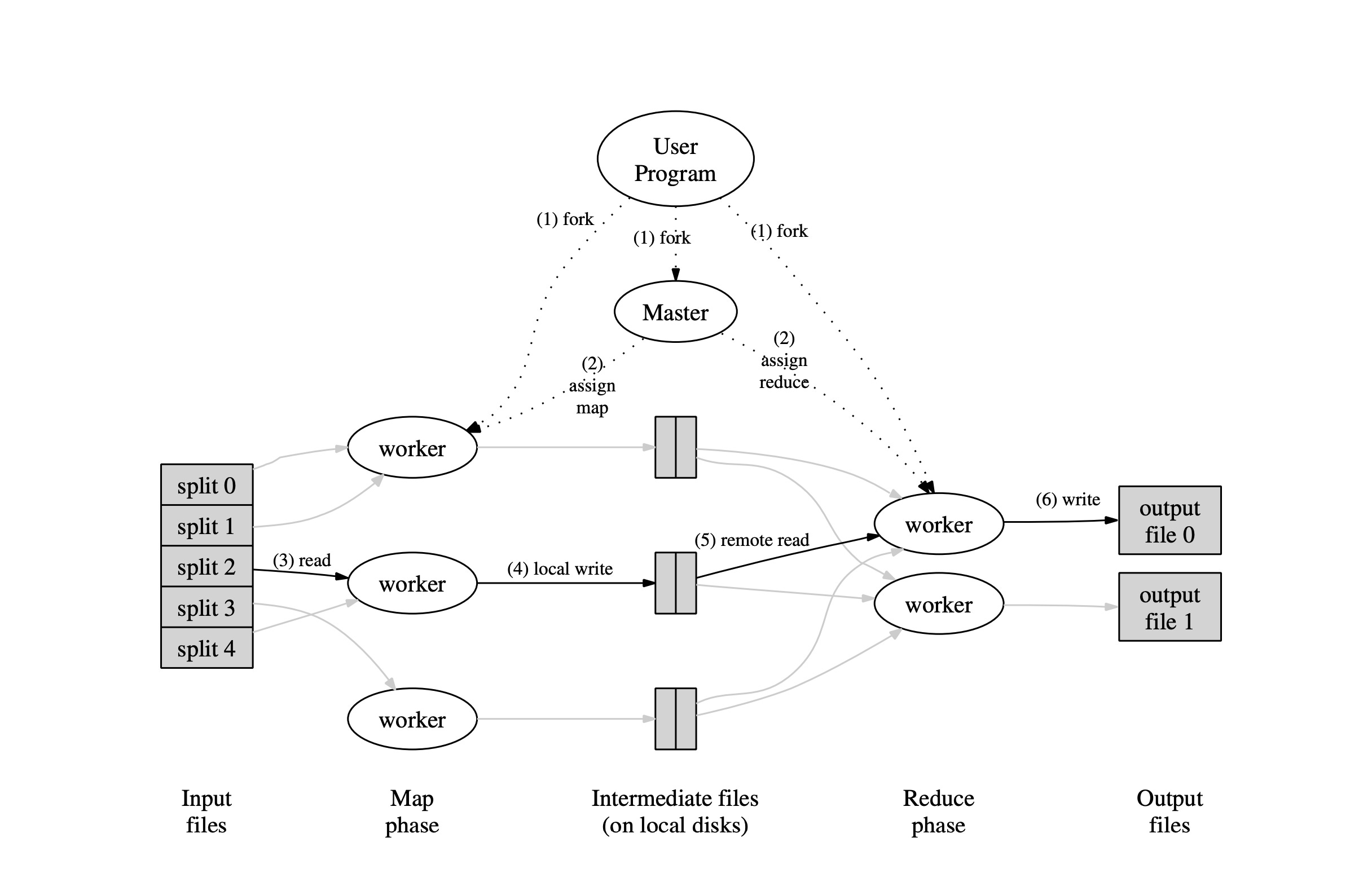
The library takes the user program and splits the input files into multiple chunks
chunk sizes are normally 16 MB to 64 MB
Then the library starts up multiple copies of the program on a cluster of machines
One copy is called the Master copy and this is responsible to assign work to the remaining copies called workers.
There are M map tasks and R reduce tasks to assign
Master picks idle workers and assigns them a task (either map or reduce)
A worker who is assigned a map task
reads the split input
parses key/value pairs from the input and passes each value to user given Map function
the intermediate results given by the map function are buffered in memory
The intermediate results in memory are periodically written to local disks partitioned in R regions by the partitioning function
The location of these buffered pairs are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
The reduce workers are notified about the location of the buffered pairs and use RPCs to read this buffered data
After reading the data the workers sort it by the intermediate keys so that all occurrences of the same key are grouped together
sorting is NEEDED because typically many different keys map to the same reduce task.
If the amount of intermediate data is too large to fit in memory an external sort (like merge sort, see the reference for more details) is used
The reduce worker then iterates over this sorted data and for each unique key it passes the key, value to the reduce function. The output of this function is appended to the final output file for this reduce partition
After all this drama the MapReduce call returns backs to user code
The output is available in R output files, typically we don’t need to combine these R files
They can be passed an input files to another MapReduce call
Master Data Structures
For each map and reduce task the master stores the state (idle, in-progress or completed) and the identity of worker machine (for non-idle tasks)
For each completed map task, the master stores the location and sizes of the R intermediate file regions, updates to this data are received as map tasks are completed
Fault tolerance
Worker Failure
Master pings every worker periodically
if no response is received in a fixed interval then the worker is marked as failed
Any map task that the worker did are reset back to initial idle state and become eligible to be picked up from other workers, the same happens in the case of reduce
If worker A performs a map task and fails and the same task is later picked up by worker B all the workers performing the reduce tasks are notified about re-executing. Any worker attempting to read data will now read from worker A
Master Failure
We can use checkpointing (similar to what we read on GFS) and everytime master fails it reads from the checkpoint on the disk and starts again
Right now Google feels that since there is only one master failure is less likely and the current implementation aborts this MapReduce computation
Clients can check for this condition and trigger a retry
Semantics in the Presence of Failures
When the user provided map and reduce functions are deterministic we get the same output as we would get if our program runs sequentially without any fault
⚠️ A deterministic function is a function that always returns the same result when given the same input values and database state
To achieve this we rely on the atomic commits of the map and reduce task
Each in-progress task writes to a temporary private output file
Reduce task → 1 file
Map task → R such file (R is the number of reduce tasks we need)
When map task is over it sends a message to the master and includes the name of these R temp files
If master receives completed message of an already completed task then it ignores it else it stores it in its data structure
When reduce task completes it AUTOMATICALLY RENAMES its temp output file to final output file
If same reduce function is run on multiple machines then the same rename function is executed multiple times for the same output file
We rely on the atomic rename operation provided by the underlying file system (GFS) to guarantee that the final file system state contains just the data produced by one execution of the reduce task
Most of the time both the map and reduce functions are deterministic and everything is clear but when its not the system still works reasonably
In the non-deterministic case the
the output of a particular reduce task R1 is equivalent to the output for R1 produced by a sequential execution of the non-deterministic program
the output for a different reduce task R2 may correspond to the output for R2 produced by a different sequential execution of the non-deterministic program.
⚠️ non-deterministic functions may return different results every time it is called, even when the same input values are provided.
Consider map task M and reduce tasks R1 and R2. Let e(Ri) be the execution of Ri that committed (there is exactly one such execution). The weaker semantics arise because e(R1) may have read the output produced by one execution of M and e(R2) may have read the output produced by a different execution of M.
Locality
Network bandwidth is a scarce resource in our computing environment
Google conserves bandwidth by taking advantage of the fact that the input data is stored on the local disks of machines that make up the cluster
Now we know that in GFS
a file is divided into 64MB blocks
and a copy of file is stored on multiple machines
The map reduce master takes the location information of input files into account and attempts schedule a map function task on machine that has a copy of the files
If it fails it goes to another machine with a copy of the file
Task Granularity
We subdivide the map phase into M pieces and the reduce phase into R pieces
Ideally M and R are much much greater than the number of worker machines
Having each worker perform multiple tasks improves dynamic load balancing and also speeds up recovery
Example case : The many map tasks completed by the failed worker now can be spread out across all other machines
The master has to make O(M + R) scheduling decisions and keeps O(M*R) state in memory, hence the value of M and R need to have a limitation
Often R is constrained by users because the output of each reduce task ends up in a separate output file.
In practice M is chosen such that each input task is roughly 16 MB to 64 MB of input data and R is made a small multiple of the number of worker machines we expect to use.
Example Numbers of M, R and workers
M = 200,000
R = 5,000
number of workers = 200
Backup Tasks
The completion time of map reduce is increased due to something called a straggler
A machine that takes an unusually long tiem to complete one of the last few tasks is called a straggler
Stragglers come up for a variety of reasons
A machine with a bad disk may get frequent errors that slow its read performance from 30MB/s to 1MB/s
Some other task might be scheduled so the MapReduce tasks are taking time
To avoid the problem of stragglers,
when a MapReduce task is close to completion the master schedules backup executions of the remaining in-progress tasks
The task is marked as completed when the primary or backup task completes
It is observed that this significantly reduces the time to complete large MapReduce operations.
Refinements
Partitioning Function
At the application level the person using MapReduce specifies how many reduce jobs / output files he wants.
MapReduce generally does a good job of partitioning data across these tasks using its default hash function on the intermediate key
hash(key) mod R.In some cases it is better to partition data by some other function of key
Example
Situation : output keys are URLs, and we want all entries for a single host to end up in the same output file.
partition function :
hash(Hostname(urlkey)) mod R
Ordering Guarantees
It is guaranteed that within a partition the intermediate key/value pairs are processed in increasing key order
This makes it easy to generate a sorted output file per partition
This help the output file to support efficient random lookups by key
Combiner Functions
Sometimes, the same intermediate data (like word counts) is repeated many times during the map phase in MapReduce.
If the Reduce function (which combines the data) is both commutative (order doesn't matter) and associative (grouping doesn't matter), this repetition can be optimized.
Example: For word counting, a common MapReduce task, many instances of the same word (e.g., "the") will be counted by different map tasks. These counts are then sent to a single reduce task to be added together.
To reduce the amount of data sent over the network, a Combiner function can be used. It partially merges data on the map task machine before sending it to the reduce task.
The Combiner function runs on the same machine as the map task, and it usually uses the same code as the Reduce function.
The main difference between the two is that the output of a Reduce function goes to the final output, while the output of a Combiner function is sent to the Reduce task as an intermediate step.
Using a Combiner function can significantly speed up certain MapReduce operations by reducing the data that needs to be transferred.
Side Effects
Sometimes, users of MapReduce need to create extra files as additional outputs from their map or reduce operations.
The application writer is responsible for ensuring that these extra files are created in a way that is both atomic (completing fully or not at all) and idempotent (producing the same result if repeated).
A common approach is to write the output to a temporary file and then rename it once the file is fully created.
⚠️ MapReduce does not support atomic two-phase commits for multiple output files produced by a single task. This means that if you need to ensure consistency across multiple files, your task should be deterministic (producing the same output each time it runs).
In practice, this limitation has not caused problems.
Input and Output Types
The MapReduce library can read input data in various formats.
One example is "text mode," where each line of a file is treated as a key/value pair—the key is the line's position in the file, and the value is the content of the line.
Another common input format involves a sequence of key/value pairs that are sorted by key.
Each input type knows how to divide itself into parts for processing.
For example, in text mode, it ensures that splits occur at line boundaries, not in the middle of a line.
Users can create custom input types by implementing a simple reader interface, although most people use predefined types provided by the library.
The reader doesn't have to get data from a file. It can also read data from other sources, like a database or in-memory data structures.
The MapReduce library also supports different output formats, and users can easily add new types by writing custom code.
Skipping Bad Rows
Sometimes, the Map or Reduce functions in MapReduce crash consistently on certain records due to bugs in the user’s code. This can stop the entire MapReduce operation.
The best solution is to fix the bug, but this isn't always possible, especially if the bug is in a third-party library without available source code.
If it's acceptable to skip a few records, like when analyzing large datasets, MapReduce offers an optional mode that detects and skips records causing crashes.
Each worker process in MapReduce has a signal handler that catches specific errors, like segmentation faults.
Before running a Map or Reduce operation, MapReduce stores the sequence number of the current record. If the code crashes, the signal handler sends a message with this sequence number to the MapReduce master.
If the same record causes multiple crashes, the MapReduce master will instruct the system to skip that record in future attempts, allowing the operation to continue.
Counters
MapReduce library includes a feature called the "counter facility" to keep track of how often various events happen.
example : you can count the total number of words processed or the number of German documents indexed.
To use this feature, user code creates a named counter and then increments it as needed during the Map and/or Reduce functions.
example : you can create a counter to count capitalized words.
The counters from different worker machines are sent to the master periodically. The master adds up these counter values from successful tasks and provides them to the user when the operation is done.
The current counter values are shown on the master status page so that users can monitor the progress of the computation in real-time.
When adding up the counter values, the master ensures that duplicate executions of the same task (which can happen due to backup tasks or re-execution after a failure) don't lead to double counting.
Some counters are automatically managed by the MapReduce library, like the number of input key/value pairs processed and the number of output key/value pairs produced.
Users find the counter facility useful for checking the correctness of their MapReduce operations. For instance, they might want to verify that the number of output pairs matches the number of input pairs, or that the percentage of German documents processed is within an acceptable range.
Aggregation at scale : A real life use-case of map reduce
I came across an interesting blog from Sharechat that talks about how they solved a problem that they faced using map reduce. Below is a TLDR of the problem and how they used map reduce
Streaming Aggregations at Scale
The problem
Managing high-frequency counters (like views and likes) at the scale of ShareChat+Moj (100k+ updates/sec per app) led to database instability, latency spikes, and hotspotting issues in our KV stores.
Use of Map Reduce
To solve the problem of reducing database load and handling counter updates efficiently, the team turned to a concept called MapReduce, which was originally introduced by Google. Here’s how they used it:
Map Step:
They grouped the data by specific categories, like
<counterType, entityId>.For example, if you're counting likes on a post (where
entityIdis the post ID), all likes for that post would be grouped together. This is called rekeying.
Reduce Step:
After grouping, they combined (or aggregated) these values together.
For instance, if multiple updates came in for the same post, they would sum up all the likes before saving it.
This process allowed them to reduce the number of database calls by processing and combining the data in batches, which helps in managing the heavy load more efficiently.
To implement this, they used Kafka Streams (a tool designed to handle streaming data) because it was easy to integrate with their existing setup. While they considered other tools like Apache Flink, Kafka Streams was simpler to manage and met their needs effectively.
In summary, MapReduce helped by grouping and aggregating data before saving it, significantly reducing the load on their databases.
Resources :
The paper was an interesting read with a lot of focus on implementation, there is a sample c++ code at the end of the paper that readers can refer. Below are a few resources that might help you understand the paper better
A sample implementation : https://github.com/AkhileshManda/MapReduce
Interesting slides : https://courses.cs.washington.edu/courses/cse454/05au/slides/08-map-reduce.pdf
External sort : https://www.geeksforgeeks.org/external-sorting/
An introduction lecture given at Berkely:
Deterministic v/s Non-Deterministic in SQL : https://www.geeksforgeeks.org/deterministic-and-nondeterministic-functions-in-sql-server/