

The premise
Ever wondered what makes platforms like TikTok and Instagram so addictive? The secret lies in their insanely powerful recommendation systems. These systems determine how engaged you’ll be during your current session by predicting what content you’ll love next. Since people enjoy exploring a variety of short-form content, the recommendations need to adapt in real-time—whether it’s based on what you’re watching right now or your interactions (likes, comments, shares) during the session.
This is exactly the problem TikTok set out to solve. Enter Monolith: a next-generation recommendation system designed to handle real-time updates and massive scale, ensuring that every swipe feels personalized and engaging.
The beginning
I hope the problem is clear. Now it is important to understand why some of the existing deeplearning frameworks like PyTorch or TensorFlow don’t help that much with this problem.
Static vs. Dynamic Features: Recommendation systems deal with sparse and dynamic data (e.g., user interactions that change constantly). Frameworks like TensorFlow and PyTorch are designed for dense computations and static parameters, which don’t work well for this kind of data. Tweaking these frameworks for recommendations can hurt the model’s performance.
Batch Training vs. Real-Time Feedback: Traditional frameworks separate training and serving into two distinct stages. This means the model can’t learn from user feedback in real-time, which is critical for recommendations.
Now let us try to get our heads around the things that actually make this problem complicated
Sparsity and Dynamism
Recommendation systems rely heavily on sparse categorical features (like user IDs, video IDs, etc.). Some of these features appear very rarely, while others (like popular videos or active users) appear frequently. To use these features in machine learning models, they’re typically mapped to a high-dimensional embedding space. However, this approach creates two big problems:
Memory Issues:
Unlike language models (where the vocabulary is limited), recommendation systems deal with millions or billions of users and items. This creates a massive embedding table that’s too large to fit into a single machine’s memory.
The embedding table keeps growing over time as new users and items are added, but traditional frameworks use fixed-size dense variables to store embeddings, which can’t handle this growth.
Hash Collisions:
To save memory, many systems use low-collision hashing to map IDs to embeddings. This works under the assumption that IDs are evenly distributed in frequency, and collisions (where two IDs map to the same embedding) won’t hurt model quality.
In reality, recommendation systems have a long-tail distribution: a small group of users or items dominate the interactions, while most others are rare. This uneven distribution increases the chances of hash collisions, which degrade model performance over time.
To solve these problems, production-scale recommendation systems need:
The ability to capture as many features as possible in their parameters.
The flexibility to adjust the size of the embedding table dynamically as new users and items are added.
💡An embedding space is a high-dimensional vector space where categorical features (like user IDs or video IDs) are mapped into dense, continuous vectors. These vectors capture relationships and patterns between features, making them easier for machine learning models to process.
💡An embedding table is a lookup table that stores these dense vectors, mapping each unique categorical feature (e.g., user ID) to its corresponding embedding. It’s essentially a key-value store where the key is the feature (e.g., "User123") and the value is its embedding vector.
Non-stationary Distribution
User behavior changes much faster than visual or linguistic patterns. For example, a user interested in one topic today might switch to something completely different tomorrow. This rapid change in user preferences is called Concept Drift. To keep up with these changes, recommendation systems need to update their models in real-time using the latest user feedback. This ensures the recommendations stay relevant and engaging.
By using a collisionless hash table and a dynamic feature eviction mechanism, Monolith ensures that every feature gets a unique embedding and outdated features are removed to save memory.
Enable real-time updates: Monolith integrates online training, where user feedback from the serving phase is immediately used to update the model, keeping it aligned with the latest user interests.
Thanks to these features, Monolith outperforms systems that use traditional hashing techniques (which suffer from collisions) while using similar amounts of memory.
The Design
Monolith’s architecture is inspired by TensorFlow’s Worker-ParameterServer (Worker-PS) setup (refer to Figure 2), where machines have two roles:
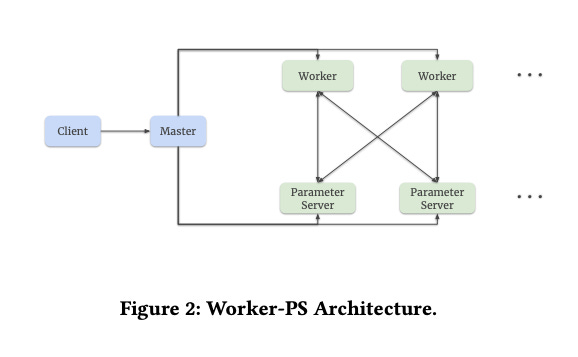
Workers: Perform computations (like calculating gradients) based on the model’s computation graph.
Parameter Servers (PS): Store and update model parameters, such as weights and embeddings.
In recommendation systems, parameters are divided into two types:
Dense Parameters: These are the weights and variables in the neural network (e.g., layers like fully connected or convolutional layers).
Sparse Parameters: These are the embedding tables that map sparse features (like user IDs or video IDs) to dense vectors.
Both dense and sparse parameters are stored on the Parameter Servers. However, Monolith introduces a key innovation for sparse parameters: a highly efficient, collisionless, and flexible HashTable. This replaces TensorFlow’s default handling of sparse features, which isn’t optimized for real-time updates.
To address TensorFlow’s limitation of separating training and inference, Monolith adds online training. This ensures that parameters are synchronized between the training Parameter Servers and the serving Parameter Servers in near real-time. Additionally, Monolith includes fault tolerance mechanisms to ensure the system remains robust even if something goes wrong.
The collisionless hash table
Now lets get into one of juicy parts of the system
Monolith has a rule avoid cramming information from different IDs into the same fixed-size embedding.
Using TensorFlow’s default Variable for this leads to ID collisions, where multiple IDs end up sharing the same embedding. This problem gets worse as new IDs are added and the embedding table grows.
To solve this, Monolith introduces a custom key-value HashTable for sparse parameters. This HashTable uses Cuckoo Hashing under the hood, which ensures that new keys (IDs) can be inserted without colliding with existing ones. Cuckoo Hashing provides:
Worst-case O(1) time complexity for lookups and deletions.
Expected O(1) time complexity for insertions.
Here’s how Cuckoo Hashing works:
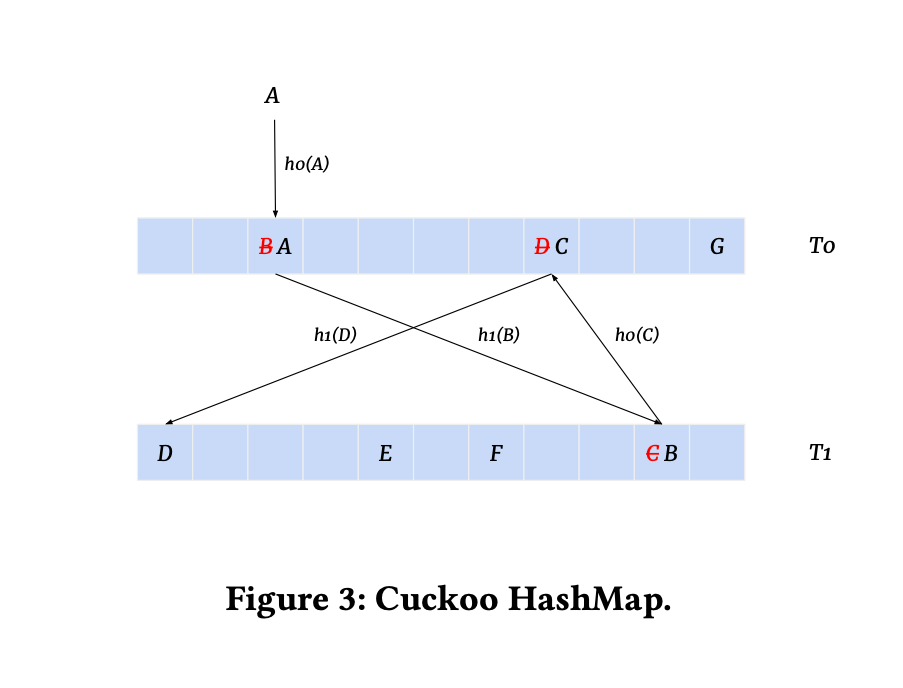
It maintains two hash tables (T0 and T1) with different hash functions (h0 and h1).
When inserting a new element, it tries to place it in T0 using h0. If the slot is occupied, it evicts the existing element and tries to place it in T1 using h1. This process repeats until all elements are placed or a rehash is triggered.
To reduce memory usage, Monolith avoids inserting every new ID into the HashTable. Instead, it filters them based on two observations:
Infrequent IDs: IDs that appear only a few times contribute little to model quality because their embeddings are underfit (not trained enough). Removing these IDs doesn’t hurt the model.
Stale IDs: IDs from old or inactive users/videos are rarely used and don’t contribute to the current model. Storing their embeddings wastes memory.
Based on these observations, Monolith uses two filtering methods:
Occurrence-based filtering: Only IDs that appear above a certain threshold (a tunable hyperparameter) are admitted into the embedding table.
Probabilistic filtering: A probabilistic method further reduces memory usage by randomly filtering out some IDs.
The system flow
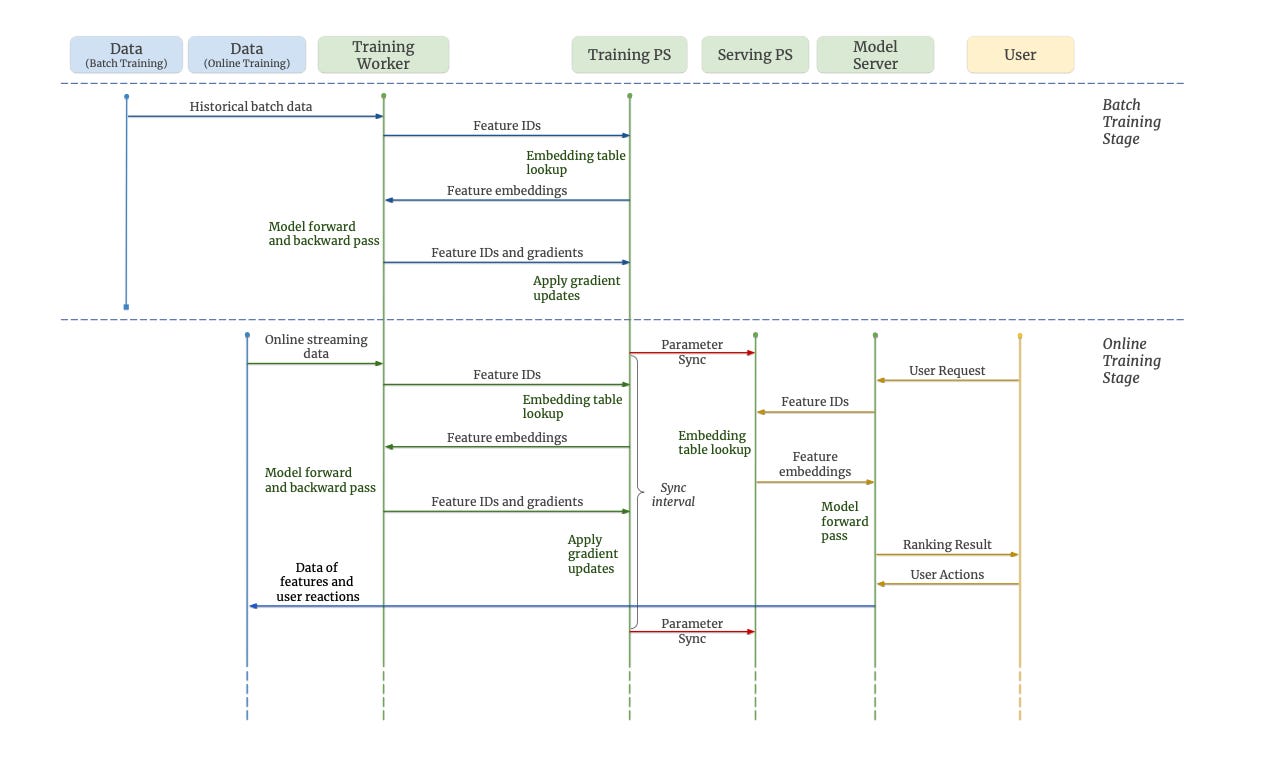
There a broadly 2 stages that you can see from the above diagram
Batch Training Stage:
This stage works like a standard TensorFlow training loop.
In each training step:
A training worker reads a mini-batch of historical training examples from storage.
It requests the current model parameters from the Parameter Servers (PS).
It performs a forward pass (computing predictions) and a backward pass (computing gradients).
Finally, it pushes the updated parameters back to the training PS.
Unlike traditional deep learning tasks, Monolith trains the dataset only once (one pass). This stage is useful when the model architecture changes or when retraining on historical data is needed.
Online Training Stage:
Once the model is deployed for online serving, training doesn’t stop—it switches to the online training stage.
Instead of reading data from storage, the training worker consumes real-time data (e.g., user interactions like clicks or views) on-the-fly.
It updates the training PS with this new data.
The training PS periodically synchronizes its parameters with the serving PS, which immediately reflects these updates in the recommendations shown to users.
This allows the model to adapt in real-time based on user feedback, ensuring recommendations stay relevant and engaging.
Monolith is designed to switch between batch training and online training easily. This flexibility is enabled by its streaming engine, which uses a combination of Kafka (a distributed messaging system) and Flink (a stream processing framework). Here’s how it works:
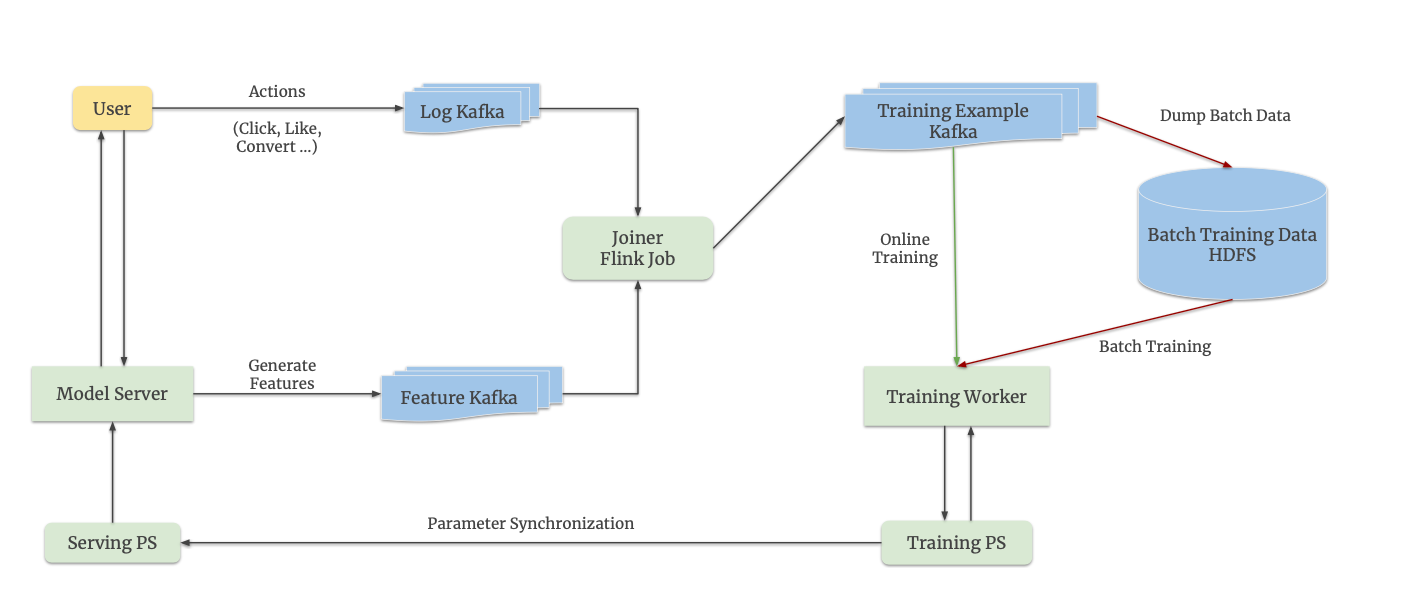
Data Collection:
Two Kafka queues are used to log data:
User Actions Queue: Logs user interactions like clicks, likes, or views.
Features Queue: Logs features (e.g., user IDs, video IDs, timestamps) associated with those actions.
Online Feature Joiner:
A Flink streaming job acts as the online feature joiner. It combines (joins) the features and labels (from user actions) to create training examples.
These training examples are written to another Kafka queue.
Training Data Consumption:
Online Training: The training worker directly reads training examples from the Kafka queue in real-time.
Batch Training: A separate job dumps the training examples from Kafka to HDFS (a distributed file system). Once enough data accumulates in HDFS, the training worker retrieves it and performs batch training.
Parameter Synchronization:
Updated parameters from the training PS (Parameter Server) are periodically pushed to the serving PS.
This ensures that the latest model updates are reflected in the recommendations shown to users.
Let’s talk a bit more about the Joiner
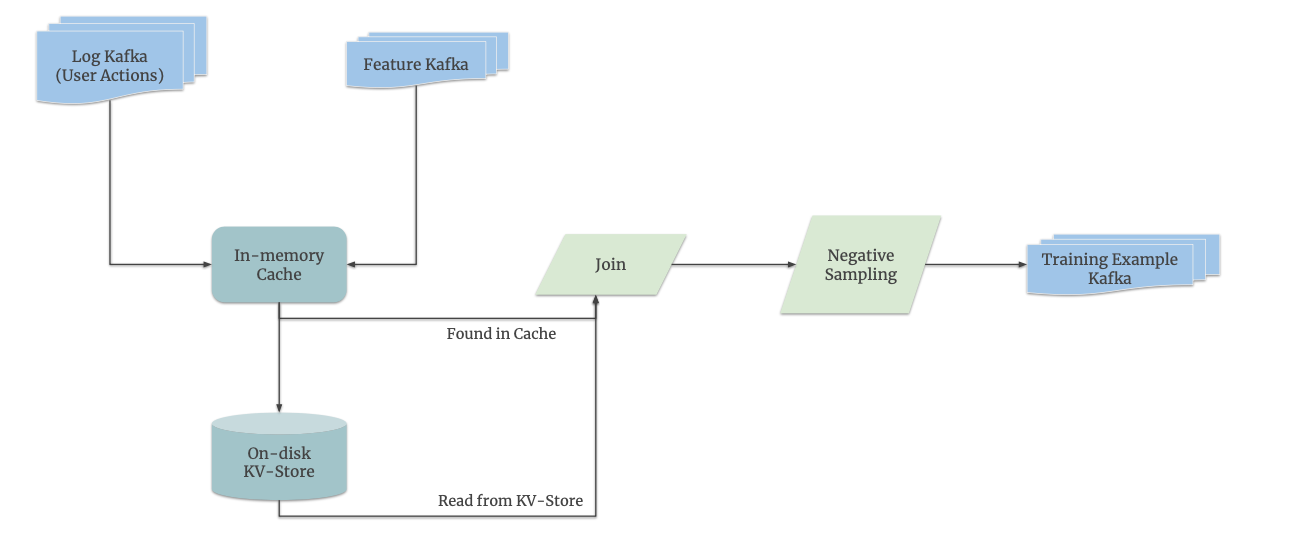
The Online Joiner is the component that pairs user actions (e.g., clicks, likes) with their corresponding features (e.g., user ID, video ID) to create training examples.
General problems with the joiner
Out-of-Order Data:
User actions and features may arrive out of order (e.g., a feature log arrives before the corresponding user action).
To handle this, each request is assigned a unique key, ensuring that user actions and features are correctly paired.
Lag in User Actions:
Users may take days to perform an action (e.g., buying an item they saw days ago).
Storing all features in memory is impractical because it would exhaust memory quickly.
Monolith uses an on-disk key-value storage to store features that haven’t been paired with user actions yet. When a user action arrives, the system first checks the in-memory cache and then the on-disk storage if the feature isn’t found in memory.
Imbalanced Data Distribution:
In recommendation systems, negative examples (e.g., skipped videos) vastly outnumber positive examples (e.g., liked videos).
To address this, Monolith uses negative sampling, which reduces the number of negative examples during training. However, this changes the underlying data distribution, making the model biased toward predicting positives.
To correct this bias, Monolith applies log odds correction during serving, ensuring the model remains an unbiased estimator of the original distribution.
Challenges with Sparse and Dense Parameters:
Sparse parameters (e.g., embeddings for user IDs or video IDs) dominate the model size but are only updated for a small subset of IDs in a short time window.
Dense parameters (e.g., neural network weights) move much slower because momentum-based optimizers (like Adam or SGD with momentum) accumulate updates over a large dataset.
This imbalance requires careful handling to ensure both sparse and dense parameters are trained effectively.
Fault Tolerance
In a production environment, fault tolerance is crucial to ensure the system can recover from failures. Monolith is designed to handle Parameter Server (PS) failures by periodically taking snapshots of the model’s state. These snapshots serve as checkpoints that can be used to restore the system in case of a failure.
However, choosing the snapshot frequency involves a trade-off:
Model Quality:
More frequent snapshots reduce the amount of data lost in case of a failure, which helps maintain model quality.
For example, if snapshots are taken every hour, the system loses at most one hour of updates during recovery.
Computation Overhead:
Taking snapshots of a multi-terabyte model is resource-intensive. It involves:
Memory Copy: Copying large amounts of data from memory to disk.
Disk I/O: Writing the snapshot to disk, which can be slow and costly.
To balance these factors, Monolith takes snapshots once a day. While this means a PS could lose up to one day’s worth of updates in case of a failure, experiments show that the resulting performance degradation is tolerable.
The experiments
To test their system TikTok conducted several experiments at pro-duction scale and A/B test with live serving traffic to evaluate and verify Monolith from different aspects.
The experiment aimed to the answer the following questions: (1) How much can we benefit from a collisionless HashTable? (2) How important is realtime online training? (3) Is Monolith’s design of parameter synchronization robust enough in a large-scale production scenario?
The team conducted experiments across two distinct environments: the widely-used MovieLens-25M dataset and a production system serving millions of users. This dual approach provided insights from both controlled and real-world scenarios.
MovieLens Dataset Analysis
The researchers selected MovieLens-25M as their benchmark dataset, comprising 25 million movie ratings from 162K users across 62K movies. The team implemented a DeepFM model and established a comparative study between:
Standard embedding tables without collisions
MD5-hashed embeddings with intentional collisions
The findings revealed significant collision rates: 7.73% for user IDs and 2.86% for movie IDs. In practical terms, this meant that approximately one in every 13 users shared an embedding with another user.
Production Environment Insights
The production environment presented more complex challenges:
The system managed approximately 1000 embedding tables
The original ID space extended to 2^48
Real-time serving requirements demanded optimal performance
The baseline implementation employed a strategic hashing technique: decomposing each ID into two components using modulo and division operations by 2^24, then combining their embeddings. This approach effectively reduced the table size from 2^48 to 2^25.
Online Training Experimental Setup
The team used the Criteo Display Ads Challenge dataset (fancy name, I know, but it's basically just a bunch of click data spread over a week). Here's what they did:
Took 7 days worth of data
Used 5 days to train their initial model (like teaching a kid the basics)
Used the last 2 days to test different update frequencies (like giving the kid pop quizzes at different intervals)
They tested three different update speeds:
Every 5 hours
Every 1 hour
Every 30 minutes
The Real-World Test
But they didn't stop at just lab experiments. They went full send and tested this on a real production system with actual users clicking around. It's like testing a new recipe - first you try it at home, then you serve it at a dinner party!
Results
The results were pretty interesting, especially when it came to how they handled different IDs in the system:
Models that didn't squish different users into the same bucket (that's what they mean by "collisionless") consistently did better
This held true whether they:
Trained for longer
Waited to see if things would change over time
And get this - even though they were giving each user their own unique space (which you might think would make things messy), the model didn't get confused or overfit
Experiment to find correct update frequency
The team conducted experiments using the Criteo Ads dataset and found a clear correlation between update frequency and model performance:
Experimental Results
5-hour update interval: 79.66% ±0.020 AUC
1-hour update interval: 79.78% ±0.005 AUC
30-minute update interval: 79.80% ±0.008 AUC
The results consistently showed that increased synchronization frequency led to improved model performance. This finding held true both in controlled experiments and production A/B tests.
System Architecture Optimization
Based on these insights, the team implemented a dual-update strategy:
Sparse parameters (user-specific): Minute-level updates
Dense parameters (global features): Daily updates during low-traffic periods
This architecture required approximately 400MB per minute of data transfer (based on 100,000 ID updates with 1024-dimensional embeddings).
Reliability Considerations
A particularly interesting finding emerged regarding system reliability. Initially, the team assumed frequent parameter server snapshots would be necessary to maintain model quality. However, their research revealed unexpected system resilience:
Key Findings
With a 0.01% daily PS machine failure rate across 1000 servers
Impact: Loss of one day's feedback from approximately 15,000 users every 10 days
Result: Negligible impact on model performance
This discovery led to a significant optimization: reducing snapshot frequency without compromising model quality. The robustness was attributed to:
Minimal impact on sparse features (affecting only 0.01% of DAU)
Slow-changing nature of dense variables making daily losses negligible
Practical Implications
These findings have important implications for production systems:
More aggressive update schedules for user-specific parameters
Reduced backup frequency requirements
Optimized resource allocation
Better balance between computation costs and model performance
Conclusion
The paper was nice and an easy read, the architecture was easy to grasp but what excited me the most was the experiments that the team ran and the findings from the results . I also came across an interesting blog from Meta on how they improve instagram’s reccomendation model
Cheers until the next paper!
Resources
Paper : https://arxiv.org/pdf/2209.07663
Meta’s blog : https://engineering.fb.com/2023/08/09/ml-applications/scaling-instagram-explore-recommendations-system/
Very nice short brief notes on the paper - https://haneulkim.medium.com/paper-review-monolith-tiktoks-real-time-recommender-system-72b90bece653