
The Google File System
Brief overview of The Google File System Paper



Hey folks! Welcome to #0 of project whitepaper, this is our attempt at understanding and trying to implement some of the very informative and educative whitepapers out there. Through this blog we want to share what we have picked up during our reading and maybe build up on a few of the ideas. Hope you find our first blog informative. Let us start understanding the Google File System.
Why GFS at the very first place ?
Every file system aims at achieving the performance, scalability, reliability, and availability, so does google, they wanted to do this but they saw many problems in the previous file systems, the most important being the design that didn’t allow / made it very difficult for them to scale to multiple clients. Here are few problems that were discussed
Multiple components and machines are used to power up a file system and there are multiple chances of component failures so therefore mechanisms for constant monitoring, error detection, fault tolerance, and automatic recovery must be integral to the system, because component failures are norms rather than the exception :)
Huge Multi-GB file handling was very difficult for older systems.
Design of previous File Systems was not much scalable, due to some traditional problems lying around.
Architecture
The most interesting part of this paper was the architecture of the file system and the way they have handled multiple cases starting from basic master chunk architecture, and then scaling it upto the level where tons of users can interact with the file system easily. Let us start decoding the components and the main architecture that supports GFS.
A GFS cluster consists of a single master and multiple chunkservers and is accessed by multiple clients, where each of them is a linux commodity server. GFS divides the files into fixed size chunks which is identified by 64-bit chunk handle assigned by the master and stores these chunks on the chunk servers for reliability.
Because of the chunkservers the master is not a bottleneck to server large file requests.
Workflow

The typical workflow is as shown in the figure above, Client application interacts with the master requesting file, the master stores with itself the location of each chunk on chunkservers, and the file namespace in some datastructure. When the client requests a file, the master returns the location of chunks servers where the chunks are present and some metadata information. The client then caches this information which decreases the number of client master interactions (only till the cache expires). Once the client gets the required information it then contacts the chunkservers for the required chunks and hence retrieves the data. This is again a very basic overview of whats happening behind the scenes to get a clear picture. We will get more essence of the workflow once we understand the roles of master and chunkservers. But before that we need to know a key design parameter which is the chunk size.
Chunk Size - The Key Design Parameter of GFS Architecture
Chunksize plays a very important role in the GFS Architecture. Google chose a larger chunk size than normally used i.e., 64MB. Now you may question why such a large size for a single chunk, why would one increase its storage costs by introducting larger chunk size. Here are some good reasoning points to support it.
First, it reduces clients’ need to interact with the master because reads and writes on the same chunk require only one initial request to the master for chunk location information. The reduction is especially significant for Google’s workloads because applications mostly read and write large files sequentially.
On a large chunk the client can perform multiple operations which reduces the network overhead by persisting a TCP Connection.
It reduces the amount of metadata stored on the master making master light and allowing it to seamlessly perform other more important functions (discussed later, stay tuned 😃)
The Master
Chunk servers are not smart enough to manage everything in such a huge system, and there are tons of chunk servers which are operating on tasks, so for proper management of multiple chunkservers over multiple racks the system demanded a single master server to whom the client will interact and who is going to assign operations and lease to chunk servers.
The Master guides the client which chunkserver to talk to, post that the master has no involvement in the communication between the client and chunkservers.If any chunkservers goes down its the responsibility of master to make sure chunkservers are up to date and in good health or recover them if corrupted.
The master keeps the chunkservers in check by communicating with them regularly with Heartbeat Messages.
Metadata Storage
Master stores some metadata with it which is important for when a client interacts with it, following is the information stored in the metadata
File and Chunk Namespaces (Namespaces are very important for dividing the code into logical sessions and scope)
File to chunk mapping, so that when client requests a file it should be able to map this file to its chunks
Location of each chunks replicas (as discussed before chunk replicas are important for reliability, so master must know each chunks replicas).
All of this is kept in the memory of master, making master perform its actions faster. This also allows the master to easily scan all the chunks and replicas and perform chunk garbage collection, re-replication in the presence of chunkserver failures, and chunk migration to balance load and disk space. The master does not keep a persistent record of which chunkservers have a replica of a given chunk. It simply polls chunkservers for that information at startup.
Operation Log and its importance
Imagine you doing your final semester assignment, you are on the 100th page and all of a sudden GFS breaks 🙂. Don’t worry, GFS got your covered with its Operation Log. Logging is very important for any system, logging has been a very good mechanism for recovery of components, logging the components action and storing them regularly can help you get back from a major component failure. Master does some similar thing, it stores the logs of all the actions and before every client operation it flushes the logs altogether to some disk locally and remotely, so that even if the file system goes done Master will know how to recover the state of its own and the chunk servers back.
The major flows
Now that we have a brief understanding of some of the components and their need in the file system let us briefly understand the read and the write flow without going into too much detail
Read - Read a file from the file syste

Client uses the fixed chunk size to translate the file name and byte offset (specified by the application into a chunk index within the file)
Client sends req to the master with file name and chunk index
Master replies with chunk handle and location
Client caches this information using (file name, chunk index) as key
Client sends req to one of the replicas (closest one)
This req has chunk handle and byte range
Further reads of the same chunk require NO client-master interaction
UNTIL the cached info expires or the file is reopened
Client typically ask for multiple chunks in the same req. The master can also include the information of the following chunks immediately
Because of this we avoid several future client-master interactions at practically no cost
Write to the file system
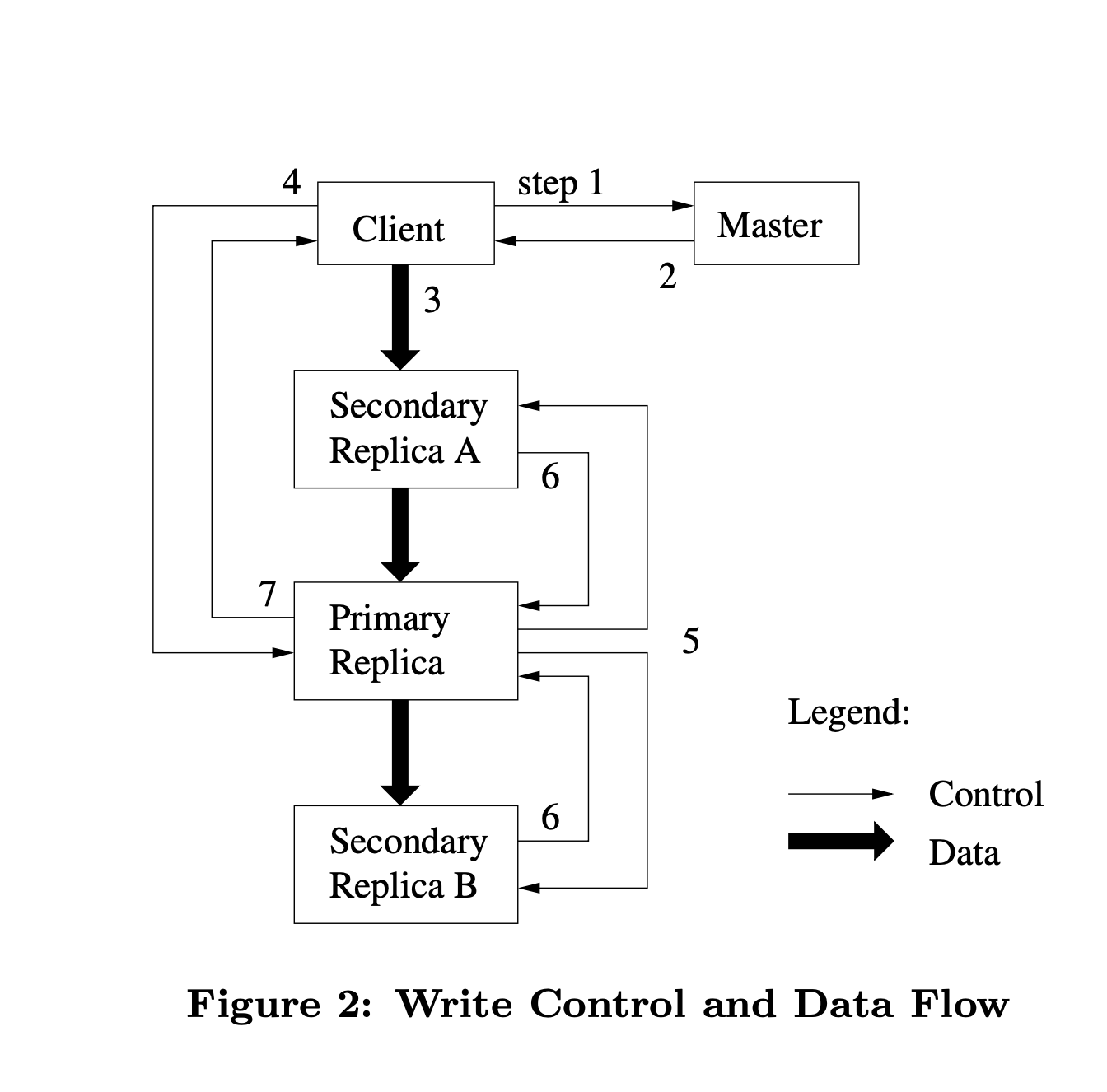
Client asks master which chunkserver holds the current lease (where is the primary located) for the chunk and the location of all other replicas
If no one has a lease master grants one to a replica it chooses
Master replies with the identity of the primary and the locations of secondary replicas.
Client caches this data for further mutations
Client needs to contact master again only when primary becomes unreachable
Client pushes data to all replicas in any order
Data is stored in the LRU cache of the replica till it is used or timed out
Separating the data flow from the control flow enables us to improve performance (how?)
schedule the expensive data flow based on the network topology regardless of which chunkserver is the primary
(All replicas send ack that they have received data)
Client sends write request to the primary, request identifies data pushed to all replicas before
primary assigns consecutive serial number it receives from multiple clients, which provides the necessary serialisation
primary applies the mutation to its own local state in serial number order
The primary forwards the write req to all secondary replicas, each secondary replica applies mutations in the same serial number assigned by the primary
All the secondaries tell the primary that they have completed the operation
Primary tells client that write is successful, any errors encountered at any of the replicas are reported to the client
A very interesting scenario is discussed in the MIT Lecture on this paper, the question is
What happens when there is no primary (chunkserver) found by the master
master needs to find the chunkserver with the latest copy of the chunk (find up to date replicas) (replica with latest version number)
master picks primary and secondary chunkserver
master increments version and writes to disk (so that it doesn’t forget)
Tells primary and secondary the data to be appended with version number
the primary and secondary servers write to the disk so that they remember
Primary picks offset
All replicas including primary are told to write at that offset
if all replicas respond yes to primary then primary is going to reply success to client
if secondary says no or error to primary then primary says no to the client
Now to find the latest copy (of the file on a chunkserver) a very interesting point to note is that, talking to all chunkservers and taking the maximum version might not work as the latest one might not respond at the time that the master talks to the chunk server. IF THE MASTER DOESN’T FIND the latest version (that it KNOWS) then it tells the application that it can’t find the latest version
A loophole is that if some replicas appended the data and some didn’t then the secondary says no to the primary and primary says no to the client, so the client expects that the write failed but while reading if we read off the latest replica we might get the new data.
Well these bring a few points to improve consistency. It is also important to remember here that Google was fine with trading off consistency if it meant the system would scale and be more performant, some points that could help improve the system are
Primary should be able to detect duplicate requests
Secondary should never return error it should do what the primary tells them, if secondary fails we need to have a mechanism where secondary is taken outside the system
Secondary shouldn’t expose data to readers until primary confirms all secondary can write it (2-face commit)
when primary crashes, there must be pending operations, the new primary might differ in these operations, the new primary should start with these so that the tail of histories are same
System either needs to send all client reads through primary or have a lease system for secondary reads to know when secondary can or cannot respond.
Resources
Well this covers a brief overview of the system works, we wanted to provide only a gist and add a few of our analysis about this. Overall the paper was a good read and to go along with it here are some nice resources :
MIT Lecture :
The paper : https://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf
An implementation that we went through : https://github.com/chaitanya100100/Google-File-System