

I have included a lot of examples from various sources to help me understand some paragraphs clearly, hence this note might be bigger than normal.
Feel free to skip through the example scenarios if at any point u have gotten the gist of what the paper is trying convey. Please read on the app for a better reading experience
Let the reading begin!
Abstract
The paper introduces a new concept called Proof Of History (PoH) - A proof for verifying order and passage of time between events
PoH is used to encode trustless passage of time into a ledger, an APPEND ONLY data structure
When used along with PoW of PoS, PoH can reduce messaging overhead in a BFT relicated state machine which results in sub-second finality times
WTF does the above statement mean?
So, the paragraph is saying that when you use Solana’s Proof of History (PoH) along with traditional systems like Proof of Work (PoW) or Proof of Stake (PoS), it helps reduce the amount of communication (or messaging) needed between nodes to make sure they all agree. This also helps the system be Byzantine Fault Tolerant, which means it can handle some bad actors or failures. And because of this setup, Solana can process transactions very quickly, with confirmation times (finality) that are less than a second.
The paper also proposes 2 algorithms that leverage the time keeping properties of PoH ledger
A PoS algorithm that can recover from partitions of any size
Efficient streaming Proof of Replication (PoRep)
The concept of PoRep and PoH gives a defence against forgery of the ledger wrt to time and storage
1. Proof of History (PoH) – Defending Time
PoH, as you know, is a way of recording time in the blockchain. Here’s how it defends against forgery:
Time-Stamped Ledger: Every event (like a transaction) on Solana is recorded with a time stamp. This makes it easy to prove when something happened.
Sequential Proofs: Since PoH is like a clock, each transaction is part of a chain of events. If someone tries to change a past transaction, they would need to modify every event after it. That’s almost impossible because everyone else on the network can see the chain and know exactly when things happened.
How it defends against forgery:
Because PoH establishes a clear sequence of events over time, it makes it very hard to fake a transaction. To forge a past transaction, an attacker would need to rewrite the whole history, which would be detected immediately.
2. Proof of Replication (PoRep) – Defending Storage
Now, let’s talk about Proof of Replication (PoRep).
PoRep is a system that proves that data has been stored correctly and replicated (copied) across multiple places. It was first developed in Filecoin, but Solana uses a similar idea for efficiency.
Efficient Replication: In a blockchain, data (like transactions) needs to be stored by many nodes (computers) to ensure that it’s safe and cannot be lost. PoRep ensures that every node has a legitimate copy of the data and didn’t fake storing it. It does this by making the node prove that it actually stores the data and hasn’t just copied someone else’s proof.
How it defends against forgery:
If a node tried to lie and say it had stored data that it didn’t, PoRep would catch the lie because the node wouldn't be able to produce a valid proof of storing the data. This proof is linked to the data itself and the time (via PoH), so forgery or tampering would be caught instantly.
Putting It All Together:
PoH (Proof of History) protects against time-based forgery because it records when every transaction happened. Changing the history would be obvious to everyone else.
PoRep (Proof of Replication) protects against storage-based forgery by ensuring that every node actually stores and replicates the correct data. No one can fake having data or skip storing it.
Together, these systems create a very strong defense for Solana’s ledger. PoH ensures that the order and timing of transactions can’t be messed with, while PoRep ensures that the data itself is properly stored and replicated.
Introduction
Traditional blockchains don’t rely on a trusted source of time. Each node uses its own clock, leading to inconsistency when accepting/rejecting messages based on timestamps.
Problem: Without a common clock, different nodes might make different decisions about message validity.
PoH (Proof of History) solves this by creating a ledger with a verifiable passage of time. This allows all nodes to rely on the same recorded sequence of events.
Benefit: It ensures consistent message ordering and timing without requiring trust between nodes.
Network Design
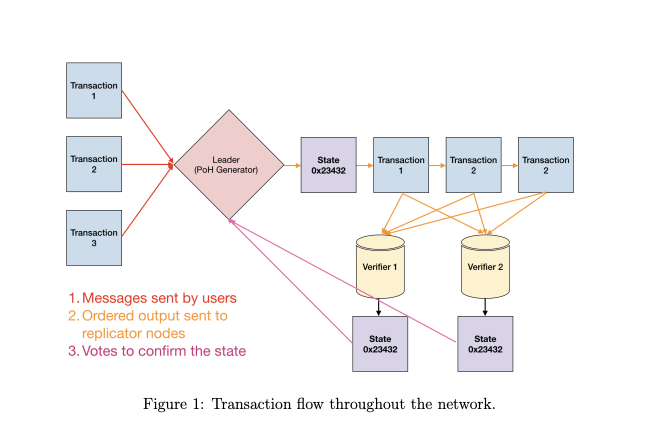
At any given time a node in the system in elected as leader (how does this election happen?) to generate a Proof of History sequence
The Leader sequences user messages and orders them such that they can be efficiently processed by other nodes in the system, maximising throughput.
It executes the transactions on the current state that is stored in RAM and publishes the transactions and a signature of the final state to the replications nodes called Verifiers.
Verifiers execute the same transactions on their copies of the state, and publish their computed signatures of the state as confirmations.
The published confirmations serve as votes for the consensus algorithm.
In a non-partitioned state, at any given time, there is one Leader in the network. Each Verifier node has the same hardware capabilities as a Leader and can be elected as a Leader, this is done through PoS based elections. (To be covered in detail below)
Consistency is almost always picked over Availability in an event of a Partition.
In case of a large partition, this paper proposes a mechanism to recover control of the network from a partition of any size.
Proof of History
Proof of History is a sequence of computation that can provide a way to cryptographically verify passage of time between two events.
It uses a cryptographically secure function written so that output cannot be predicted from the input, and must be completely executed to generate the output.
The function is run in a sequence on a single core, its previous output as the current input, periodically recording the current output, and how many times its been called.
The output can then be re-computed and verified by external computers in parallel by checking each sequence segment on a separate core.
1. Running the Function in a Sequence on a Single Core
Imagine you have a special math function that takes an input, performs a calculation, and gives an output.
In PoH, this function is run over and over again in a chain. The output from one run becomes the input for the next run.
It’s important that the function can’t be skipped or fast-forwarded. You must fully complete one calculation before starting the next.
Periodically (every so often), the system records the current result (output) and the number of times the function has been run so far.
Why this matters: Recording the result at different points ensures there’s a proof that time has passed, because it takes real time to compute these steps. This creates a verifiable chain of events, where everyone can see the order of operations.
2. Verifying the Output in Parallel
Once the sequence has been run and the outputs recorded, other computers (nodes) in the network can verify it. Instead of re-running the entire sequence from start to finish, they can divide the work.
Parallel Checking: Each computer (node) can take a different segment of the sequence (like a chunk of the chain) and re-run it to check if it was done correctly. Since the function is deterministic (always gives the same output for the same input), it’s easy to verify.
This is faster because each segment is checked independently on different cores (separate processors), so multiple segments can be verified at once. This parallel processing speeds up the verification process.
Why this matters: It allows Solana to verify the passage of time efficiently. Instead of one computer doing all the work, multiple computers can work on verifying different parts at the same time, making the system faster.
Summary of These Points:
The PoH function runs in a sequence, recording outputs and how many times it’s been run. This proves that real time has passed.
Other computers can verify the sequence by re-calculating smaller parts of it in parallel (all at the same time), which speeds up the verification process.
Imagine:
We have a blockchain network running Solana’s Proof of History (PoH). The PoH function is constantly running, creating a sequence of outputs that everyone in the network can see and verify. We’ll break this down in parts.
Part 1: The PoH Sequence
Let’s say we’re running this PoH function, and it’s producing a sequence of outputs (numbers, for simplicity):
First Output:
A1Second Output:
B2Third Output:
C3Fourth Output:
D4
These outputs represent time as it passes because each output takes a certain amount of time to calculate, and the function must be run in order. So, each output is like a tick of a clock.
Part 2: Appending Data to the Sequence
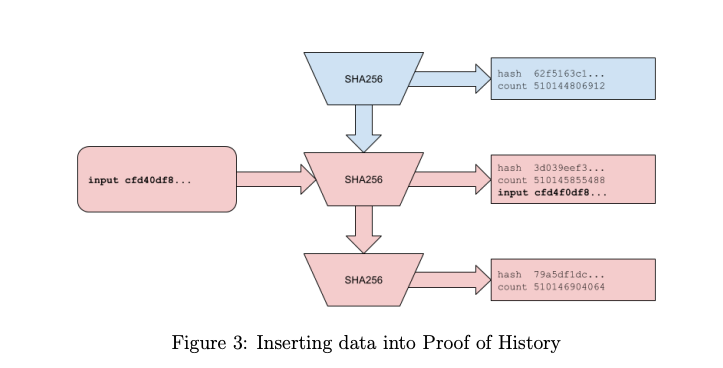
Now, say someone makes a transaction, and we want to record the fact that this transaction happened at a specific time. Instead of attaching the whole transaction (which might be too big), we take a hash of the transaction.
Hash of Transaction:
TxHash123(this is like a unique fingerprint for the transaction)
We now want to append this TxHash123 to the PoH sequence. Let’s say we append it when the PoH function is at output C3.
PoH Output at this moment:
C3Data (hash) to append:
TxHash123
By appending the transaction hash to the state of the function, we’re saying: "This transaction (or data) happened at the time represented by output C3 in the PoH sequence."
Part 3: Creating the Timestamp
Now, we have three things:
The current PoH state:
C3The index: This is the count of how many times the PoH function has run so far (in this case, it’s the third time).
The data: The
TxHash123that we just appended.
Together, these things create a timestamp that proves the transaction existed before the next PoH output (D4) was generated. This is the timestamp:
PoH Output: C3
Index: 3
Appended Data (TxHash): TxHash123
This guarantees that TxHash123 (the transaction) happened sometime before the next output, D4, was created.
Part 4: Verifying the Timestamp
Later on, someone else wants to verify that the transaction TxHash123 happened at that specific time. They can look at the PoH sequence and see:
The PoH output
C3.The index
3.The appended data
TxHash123.
They can re-run the PoH sequence up to C3 and confirm that the transaction was indeed part of the sequence at that point in time.
Part 5: Horizontal Scaling Example
Now, let’s add multiple PoH generators (nodes) to the picture.
Let’s say Node A is running its own PoH sequence (
A1,B2,C3,D4) and appends some data (TxHash123) atC3.Meanwhile, Node B is running its own PoH sequence separately (
P1,Q2,R3,S4).
To keep everything synchronized and ensure both nodes are on the same timeline, they can mix their state into each other’s sequences.
Node A takes its state (e.g.,
D4) and adds it to Node B’s sequence.Node B does the same, adding its state (
S4) to Node A’s sequence.
By doing this, both nodes are synchronized, and they both know the exact sequence of events. This allows them to horizontally scale without losing the order of events.
Summary of the Example:
PoH sequence creates a chain of outputs that represent the passage of time.
Appending data (hash) to the sequence adds a timestamp, marking when the data happened.
Multiple nodes (generators) can work in parallel, and they synchronize by mixing their PoH states to stay on the same timeline.
This way, the Proof of History ensures that data (like transactions) is recorded accurately in time and helps keep multiple nodes in sync.
Description
We have a cryptographic hash function whose outcome we cannot predict without running the function (some examples are sha256, ripemd etc) run this function for some random starting value and takes it output and pass it as input to the same function again, record the number of times the function has been called.

it is only required to publish the hash and indices at an interva

l
As long as the hash function is collision resistant, this set of hashes can only be computed in a sequence by a single computer thread
💡The sequence of hashes can only be computed on a single computer thread because each step depends on the previous one, and doing it this way ensures that time moves forward as expected, creating a reliable and unforgeable timeline.
Timestamp for events
💡Basically this is saying that when u add an event along with the hash the new hash generated acts as timestamp for this event
Step 1: Understanding the PoH Sequence Without Data
First, let’s look at the PoH sequence as if it’s running normally, without adding any extra data:
The PoH system runs a hash function, like
sha256, repeatedly. The output of one step becomes the input of the next. This creates a sequence that acts like a ticking clock.
Here’s what it might look like:
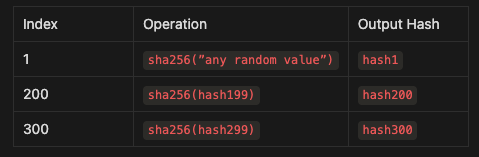
This sequence shows the hash values being calculated in order. Each index represents a step in time.
Step 2: Adding Data to the PoH Sequence
Now, let’s say something happens in the real world—like someone taking a photograph—and we want to record when this event happened in the sequence.
Event: Someone takes a photograph.
We create a hash of the photograph using
sha256, resulting in something likephotograph sha256.We combine this hash of the photograph with the current state of the PoH sequence. The combine function is simply an operation (e.g., appending or mixing the hashes) that ensures the new data (the photograph hash) becomes part of the sequence.
So, when we insert this new data, the PoH sequence might look like this:
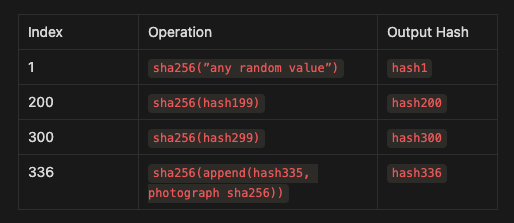
Here’s what happens:
At index 336, the sequence includes the hash of the photograph (
photograph sha256) combined with the current hash (hash335).The output (
hash336) now includes this new piece of data.
This action timestamps the photograph, showing that it existed before hash336 was calculated.
Step 3: Why Is This Important?
By appending the data (the photograph hash) to the PoH sequence at a specific point, it’s recorded that this event happened before the next hash in the sequence (
hash336) was generated.This timestamp is secure because the PoH sequence must run step by step, and you can’t jump ahead. The sequence proves the order of events because each new hash depends on the previous ones.
Step 4: Effect of Adding Data on Future Hashes
When we insert data into the sequence, it changes the output for that step and all future steps. Since the hash function uses the output of the previous step as the input for the next one:
All the hashes generated after the data insertion are influenced by the added data.
For example, when we insert
photograph sha256at index336, all the subsequent hashes (hash337,hash338, etc.) will be based on this new state. This ensures that the sequence cannot be predicted in advance and must be computed as events happen.
Step 5: Parallel Verification and Collision Resistance
Verifying the Sequence:
Other nodes in the network can verify this sequence in parallel. They can check specific segments to confirm that the insertion of the photograph happened correctly and that the sequence remained consistent after that.
Collision Resistance:
By using a collision-resistant hash function, we ensure that no one can forge this sequence. If someone tries to change any data or add false data, it will change the entire sequence, making it obvious that something is off.
It’s computationally impossible to predict what the sequence will look like in the future based on current information because we don’t know what data might be inserted next.
Step 6: Example with Multiple Events
Let’s say we have another photograph event later in the sequence:
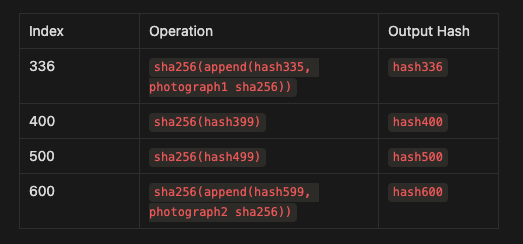
Photograph 1 was added at index 336, so we know it happened before
hash336.Photograph 2 was added at index 600, so we know it happened before
hash600.
By observing this, anyone verifying the sequence knows the exact order of events and can estimate the time between these events.
Summary
When data (like a photograph) is added to the PoH sequence, it’s combined with the current state of the sequence to create a timestamp.
This timestamp shows that the data existed before the next step in the sequence was calculated.
Future hashes depend on this data, ensuring the sequence remains secure and accurate.
Nodes in the network can verify this sequence in parallel to confirm that events occurred in the right order.
Verifying
Step 1: How PoH Is Normally Generated
When Solana’s PoH system creates the sequence, it does so sequentially. This means each hash depends on the one before it.
It takes real time to generate this sequence because the output of each step becomes the input for the next step.
For example:
hash200is based onhash199.hash300is based onhash299.And so on.
Step 2: Verifying the PoH Sequence
When verifying if this sequence is correct, the goal is to check if each hash in the sequence was calculated properly. Normally, if you did this verification one step at a time, it would take just as long as it took to generate it. But here’s where multi-core computers come in.
Step 3: Splitting the Work Across Multiple Cores
Imagine you have a computer with many processing units (cores). For example, a modern GPU might have 4000 cores. Each core can work independently, so instead of verifying the sequence in a single line like it was generated, we can split the sequence into smaller chunks and verify them in parallel.
Here’s how it works:
The sequence of hashes is divided into slices. For example, one slice might be from
hash200tohash300, and another slice might be fromhash300tohash400.Each core takes one of these slices and verifies it independently.
Let’s say we have 4000 cores available:
We split the PoH sequence into 4000 parts.
Each core verifies its part of the sequence at the same time as the others.
Step 4: Why Is This Faster?
The formula to calculate the time it takes to verify the sequence is:
Verification Time=Total Number of Hashes(Hashes per second per core) * (Number of Cores)\text{Verification Time} = \frac{\text{Total Number of Hashes}}{\text{(Hashes per second per core) * (Number of Cores)}}
Verification Time=(Hashes per second per core) * (Number of Cores)Total Number of Hashes
Because we have many cores working in parallel, the number of hashes each core needs to verify is much smaller, making the overall verification process much faster.
Example: Visualizing the Verification
Core 1 might check from
hash200tohash300.Core 2 might check from
hash300tohash400.They work simultaneously, so while one core is verifying one part, another core is doing a different part.
The diagram (Figure 4) shows how the work is distributed:
Red-colored hashes: These indicate that some event data was inserted (like in previous examples with photographs). Even though the data is added, cores can still verify these segments in parallel because they have the information needed (like the hash of the data inserted) to recompute and check that part of the sequence.
Step 5: Why Does This Work?
The PoH sequence records everything needed (hashes, data, index) for each step:
By splitting the sequence into pieces and assigning them to different cores, each core has enough information to recreate and verify its segment independently.
As long as the hash function is collision-resistant and the sequence is split correctly, this method ensures the entire sequence is verified accurately and much quicker than doing it step by step.
Summary
When the PoH sequence is generated, it’s done in order, taking time.
To verify it faster, we use multiple cores to split the work into smaller slices, so each core checks a part of the sequence simultaneously.
This parallel approach dramatically speeds up the verification process, ensuring the sequence is correct while saving time.
Horizontal scaling
We can synchronise multiple PoH generators (nodes) by mixing the sequence state from each node to each other node.
Scaling is done without sharding
The output of both nodes is necessary to reconstruct the full order of events in the system
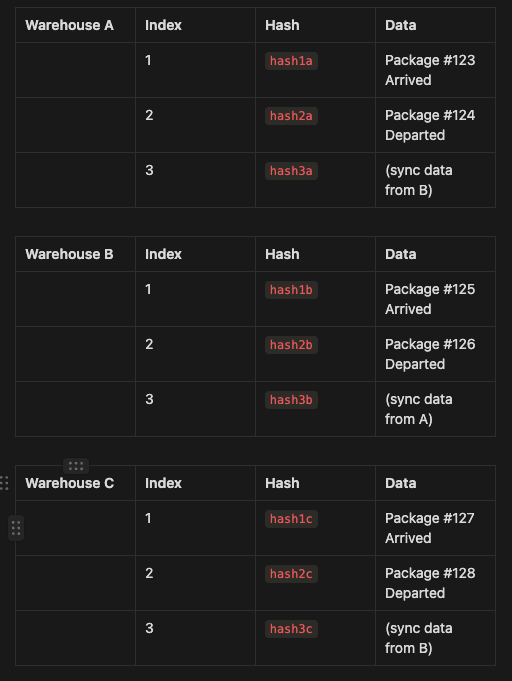
Imagine a logistics company uses a blockchain-based system to track packages. There are multiple warehouses (nodes) across different locations, and each warehouse has its own PoH generator that logs events like package arrivals, departures, and handovers.
Step 1: PoH Generators at Each Warehouse
Each warehouse (say Warehouse A, Warehouse B, and Warehouse C) has its own PoH generator:
Warehouse A logs when packages arrive or leave.
Warehouse B logs the same types of events for its own packages.
Warehouse C does the same.
Initially, each warehouse logs its events independently using its PoH generator. The sequence at each warehouse might look like this:
Step 2: Synchronizing Across Warehouses
When a package moves from one warehouse to another, the PoH generators synchronize. Here’s how it works:
Warehouse A sends a package to Warehouse B.
When Warehouse A logs the departure of the package, it also sends its latest hash (
hash2a) to Warehouse B.Warehouse B then logs this hash (
hash2a) as part of its own sequence, showing that it received a package and the last state from Warehouse A.
Now, Warehouse B’s sequence includes the state from Warehouse A, meaning that:
Events in Warehouse A (like the departure of the package) happened before the events in Warehouse B (like receiving the package).
This synchronization allows us to trace the journey of the package and verify the timeline.
Step 3: Adding Warehouse C into the Mix
Let’s say Warehouse C later receives a package from Warehouse B. They also sync their PoH generators:
Warehouse B sends its latest hash (
hash3b) to Warehouse C when it sends the package.Warehouse C logs this hash (
hash3b) into its sequence.
This forms a chain:
A ↔ B ↔ C. Even though Warehouse A and Warehouse C haven’t communicated directly, we know that events in Warehouse A happened before events in Warehouse C through their common connection via Warehouse B.
Step 4: Storing Data
All these hash sequences and data are stored on each warehouse’s system:
The data includes information about packages (like arrivals and departures) and the state information from other warehouses (like the latest hash from another warehouse’s PoH generator).
Each entry in the sequence (hash) proves that a certain event happened at that point in time and provides an exact timeline for when packages moved between warehouses.
Step 5: Verifying the Sequence
If someone needs to verify the delivery history of a package (say, to confirm its arrival at Warehouse C):
They look at Warehouse C’s PoH sequence to find the hash corresponding to when the package arrived.
The verifier can trace back through Warehouse B’s sequence (since C recorded B’s state) and all the way to Warehouse A.
Because the sequences are linked and depend on each other’s states, the verifier can reconstruct the entire journey of the package and confirm that each event occurred in the correct order.
If there are multiple cores available, the verifier can split the work:
Different cores can check the sequences at each warehouse simultaneously (e.g., one core checks Warehouse A’s sequence, another checks Warehouse B’s sequence, and so on).
This speeds up the verification process, ensuring that the entire history is accurate and matches the recorded hashes.
Summary
Data Communication: Warehouses communicate their state (hashes) to each other when packages move between them.
Data Storage: Each warehouse stores a sequence of hashes and data related to package events and synced states from other warehouses.
Verification: The system allows for quick verification using multiple processing cores, ensuring the package’s journey is traceable and accurate.
Simpler Example
Let me explain this in a simple way!
Imagine two kids, Alice and Bob, each writing down when things happen in their own notebooks:
Two Timekeepers
Alice has her notebook (Generator A)
Bob has his notebook (Generator B)
They both write down events as they see them
Sharing Information
Every so often, Alice tells Bob what she wrote
Bob also tells Alice what he wrote
They both write down what the other person told them
How it Works
Alice writes: "I saw a cat" (hash1a)
Bob writes: "I saw a dog" (hash1b)
They tell each other
Alice writes: "Bob saw a dog, then I saw a bird"
Bob writes: "Alice saw a cat, then I saw a squirrel"
Why This is Cool
Now we know what happened first:
If Alice writes about Bob's dog, the dog came before Alice's bird
If Bob writes about Alice's cat, the cat came before Bob's squirrel
Adding More Friends
Charlie can join too!
If Charlie talks to Bob, Alice can know what Charlie saw
It's like passing messages through friends
Making Things Faster
Instead of one person trying to write everything
Three people can write things at the same time
They just need to share their notes sometimes
The tricky part is:
Sometimes it takes time for Alice to tell Bob what she saw
So we might not know exactly when things happened
But we can still know what happened before what
It's like having multiple playground monitors, each watching different areas, and occasionally shouting to each other what they've seen!
Consistency
In PoH, consistency is all about making sure that the sequence of events or data entries is logged in the right order and can’t be altered or faked by anyone, even a malicious PoH generator. To enforce this consistency, clients (users or nodes in the network) reference the last hash they saw in the sequence when they add new data. This way, the sequence becomes linked and verifiable.
Step-by-Step Explanation
Client-Generated Events Reference the Last Observed Hash:
When a client (a node or user in the network) generates an event (like creating a transaction or recording some data), they don’t just record that event alone.
They append the last hash they observed in the sequence to their event data. This ensures that their event is tied to the current state of the sequence.
Why Append the Last Hash?
By appending the last hash, the client is saying, "I saw this specific state in the sequence before adding my new data."
This creates a dependency: if you want to verify the client’s event, you must also verify that the last hash they referenced is correct and actually exists in the sequence.
Preventing Malicious Behavior:
Imagine a malicious PoH generator wants to create a fake sequence or rearrange the order of events. If it tries to do this, the sequence it produces won’t match the references provided by the clients.
For example, if a client added Event1 based on
hash10a, but the malicious generator tries to move Event1 somewhere else, the reference (hash10a) won’t fit. This will be detected during verification.
Adding Signatures for Extra Security:
To further protect against tampering, clients can also sign their event data using their private keys. This signature proves that the client indeed generated that specific event based on the last observed hash.
If a malicious PoH generator tries to alter the event or its position, it won’t be able to produce a valid signature, making it clear that the sequence has been tampered with.
Verifying the Sequence
When the sequence is published, other nodes or verifiers will:
Check that the hash references in each event match the correct sequence order.
Validate the signatures attached to the events to ensure they come from legitimate clients.
Look up each hash in the sequence to confirm it was correctly referenced and has not been altered.
If everything matches up, the sequence is consistent and valid. If any part doesn’t match, it shows that the sequence might be manipulated.
Explanation Like I am 5
Let me explain this in a simple way!
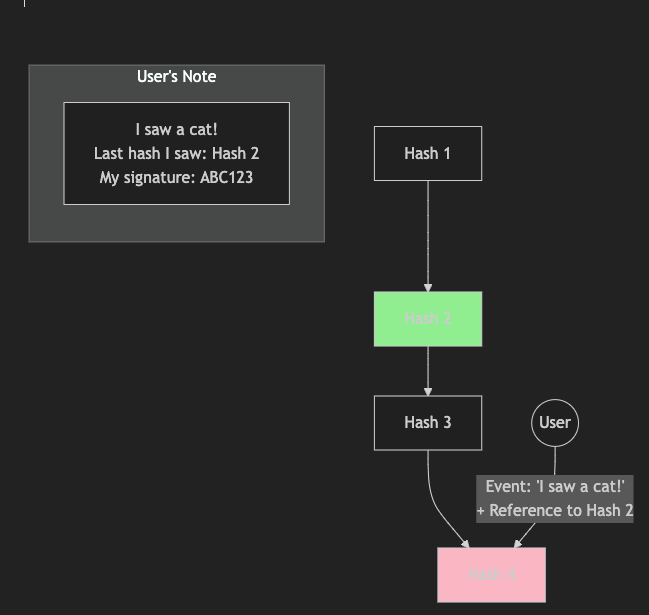
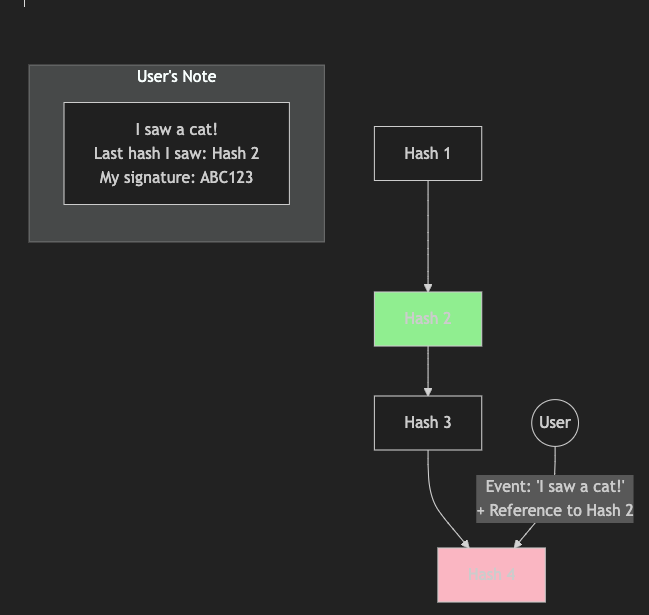
Imagine we're playing a game where everyone writes in a special diary, but we need to make sure nobody cheats by changing what was written earlier. Here's how we make it fair:
The Magic Diary
The diary writes down everything that happens
Each new entry gets a special code (hash)
These codes are like page numbers that can't be changed
How Kids Write in the Diary
When you want to write something, like "I saw a cat!"
You also write down the last code you saw in the diary
You put your special signature on it (like a fingerprint)
Why This Stops Cheating
If someone tries to change the order of things later:
Like saying the dog came before the cat
We can check your note that says "I saw the cat after code #2"
If the diary doesn't match, we know someone cheated!
Example of How It Works
The diary has entries:
Page 1: Code ABC
Page 2: Code XYZ
You write: "I saw a cat! (And I saw code XYZ)"
Now nobody can say your cat came before code XYZ
Extra Security
Your signature proves it was really you who wrote it
Like putting a special sticker only you have on your note
If Someone Tries to Cheat
They'd have to change all the pages
But they can't copy your special sticker (signature)
So everyone would know they cheated!
It's like playing with building blocks:
Each block must sit on top of the ones before it
You can't pull out a block from the bottom without everything falling down
And each block has a special sticker showing which blocks were under it
This way, everyone can be sure:
What happened first
Who wrote what
That nobody changed things after they were written
Attacks
1. Reversal Attack
This is when an attacker tries to reverse the order of events in the sequence.
For this to work, the attacker would have to delay their sequence until after the second event has happened, which could give honest nodes time to communicate with each other and identify the original, correct order.
So, the delay becomes a weak point for the attacker, making it hard for them to successfully pull off a reversal without being detected.
2. Speed Attack
To protect against attacks, multiple PoH generators (like nodes) can work together, each optimized for different tasks:
One generator could be high bandwidth, handling many events and mixing them into its sequence.
Another generator could be high speed but low bandwidth, focusing on quickly processing data and syncing with the high bandwidth generator from time to time.
This setup creates two sequences: one high-speed and one high-bandwidth. An attacker would have to reverse both, making it even harder to manipulate the sequence without being detected.
3. Long Range Attacks
These attacks involve an attacker acquiring old, discarded private keys from past users or nodes. The attacker then tries to create a falsified ledger using these old keys.
Since these private keys are no longer actively used by the original owners, the attacker could technically use them to generate fake history and make it look legitimate.
However, Proof of History (PoH) helps defend against this in two ways:
Replaying the Sequence Takes Time:
To make a convincing fake ledger, the attacker would need to replay the entire historical record of events. This is not easy.
The attacker would have to process everything at the same speed or even faster than the network originally did to catch up. If the network uses fast processors, it becomes really difficult for the attacker to recreate the sequence and overtake the network in terms of history length.
A Single Source of Time:
Solana's network uses a single historical record of events for all participants. By relying on this single source of time (PoH), it becomes difficult for an attacker to generate an alternative, fake history.
Even if they have old private keys, they still need to synchronize with this single source of time and keep up with the network’s pace, making their attack infeasible unless they have extraordinary computing power.
Additionally, PoH works alongside Proof of Replication (PoRep) to provide protection for both time (PoH) and storage (PoRep). This combination ensures the ledger is secure in terms of both the timeline of events and the space it occupies.
So, in simple terms, Long Range Attacks are when someone tries to recreate history using old keys, but PoH makes this extremely hard because they’d need to invest the same amount of time and computing power the network originally used—or even more—to pull it off.
Proof of Stake Consensus
This is for confirming of the current sequence - provided by the PoH generator, for voting and selecting the next PoH generator
The algorithm depends on messages eventually arriving to all participants within a certain timeout
Terminology
Bonds - A bond is coin that the validator commits as collateral while they are validating transactions
Slashing -
It is a penalty mechanism used in Proof of Stake (PoS) systems to punish validators (nodes that validate transactions and create new blocks) for bad behavior. It’s meant to ensure the security and reliability of the network.
Here's how it works in simple terms:
Validators are required to lock up some of their cryptocurrency as a bond or stake to participate in the consensus process.
If a validator does something malicious or incorrect, like:
Voting for multiple branches of the blockchain at the same time (trying to cheat the system), or
Acting against the rules of the network.
The network can slash or take away a part or all of their staked cryptocurrency as a punishment.
This creates a financial incentive for validators to act honestly because if they cheat, they risk losing their stake.
So, slashing is basically a way to enforce good behavior and discourage cheating in a PoS system by threatening the loss of funds.
Super Majority - A super majority is 2/3rds of the validators weighted by their bonds
Bonding
When a user (validator) wants to participate in the network and validate transactions, they need to lock up some of their coins in a bonding account.
This bond shows their commitment and serves as collateral to prevent them from misbehaving (because if they do, their bond might be slashed).
For the bond to be valid, more than two-thirds of the validators must agree that the sequence of the bonding transaction is legitimate and correct.
Before the bond becomes active, the bonding transaction must go through the blockchain, and its order or sequence needs to be confirmed by the network.
When I say the bond becomes active, I mean that the validator’s staked coins are now officially locked in the system, and the validator gains the right and responsibility to participate in validating transactions and creating new blocks
The staked coins are now locked and at risk if the validator misbehaves.
When the supermajority of validators agree on this sequence and approve it, the bond is considered valid and locked in, meaning the user can now participate as a validator.
Voting
The Proof of History (PoH) generator periodically publishes a signature (a cryptographic proof) showing the current state of the blockchain.
Each validator (bonded identity) must confirm this state by signing it themselves and publishing their own yes vote.
There is only a yes vote option—validators either agree with the state or they don’t vote.
If a supermajority (more than two-thirds) of validators confirm the state within a set time limit, the blockchain accepts this state as valid.
Unbonding
Missing N number of votes marks the coins as stale and no longer eligible for voting. The user can issue an unbonding transaction to remove them.
N is a dynamic value based on the ratio of stale to active votes. N increases as the number of stale votes increases.
In an event of a large network partition, this allows the larger branch to recover faster then the smaller branch.
Election
If the current PoH generator fails or is not functioning properly, an election is triggered.
The validator with the largest voting power is chosen as the new PoH generator.
If there is a tie, the validator with the highest public key address is selected.
A supermajority (more than two-thirds) of validators must confirm the new generator’s sequence.
If this supermajority confirmation is achieved, the new generator is established as the leader.
If the new generator fails before a supermajority is reached:
The next highest validator is selected as the new PoH generator.
Another set of supermajority confirmations is required for this new candidate.
Validators can switch their votes, but:
The switch must occur at a higher PoH sequence counter.
The new vote must reference the votes the validator wants to switch from.
If this is not done correctly, the second vote can lead to slashing.
Vote switching is only allowed at a PoH height that doesn’t already have a supermajority.
Once the Primary PoH generator is established:
A Secondary PoH generator may be elected to handle transaction processing.
The Secondary acts as a backup and will become the next leader if the Primary fails.
The platform promotes the Secondary to Primary if the Primary fails or on a predefined schedule.
Lower-rank generators are also promoted accordingly to maintain backup and continuity.
Triggers for election are
Forked PoH generators
Runtime Exceptions
Network timeouts
Slashing
Slashing is a penalty system where a validator loses their bonded coins if they behave maliciously.
If a validator votes on two different sequences, a proof of this behavior can be used to remove their bonded coins. These coins are taken out of circulation and added to the mining pool as a penalty.
If a validator votes again and includes their previous vote from a contending sequence, it won’t count as malicious behavior. Instead of slashing, this action removes their current vote from the contending sequence.
Slashing also happens if a validator votes for an invalid hash generated by the PoH generator. To ensure this, the generator may occasionally create an invalid state to check the validators. If an invalid state is detected, the system triggers a fallback to the Secondary PoH generator.
Checkout the most recent slashing transaction : https://explorer.solana.com/tx/2A6cdwon8673NKfDE4oKFjovvyp613LZKkCPbDYchxUGWoj5RkLqpCfQpmv1tkGqKZx9YLKTtNBBrRxWKnSLpeo1?cluster=testnet
Availability
Solana’s approach prefers Availability but also tries to maintain Consistency within a reasonable time window using its Proof of History (PoH).
Validators lock up coins as a stake and use this to vote on transactions.
This staking and voting process is recorded as transactions in the PoH ledger, similar to other transactions.
The votes are time-stamped, so you can see how long it takes between votes and when a validator becomes unavailable (due to a network partition).
If a partition occurs (network splits), some validators may become unreachable. To maintain availability:
If more than 2/3 of validators are available, unstaking of the missing ones is fast. They are removed quickly to keep the network going.
If the number of available validators falls below 2/3 but is still above 1/2, the unstaking takes longer. More hashes are generated before they are removed from consensus.
If less than 1/2 of the validators are available, the process becomes very slow. It takes a large number of hashes for the network to remove the missing validators and reach consensus again.
In case of a large partition, the system allows time for users to decide which partition they want to continue using.
This approach provides flexibility, giving users a chance to pick the most active partition within a reasonable human timeframe.
System Architecture Overview
Leader, Proof of History (PoH) Generator:
The Leader is an elected entity responsible for generating the Proof of History (PoH) sequence, ensuring a globally unique order for all transactions. It processes incoming user transactions, orders them efficiently, and outputs a PoH sequence. After each transaction batch, the Leader produces a signed state signature that reflects the new system state.
State Representation:
The system uses a basic hash table indexed by user addresses, storing relevant user data (such as transaction and staking information). Each entry includes user-specific details and memory requirements, with separate tables for account balances and Proof of Stake bonds.
Verifiers and State Replication:
Verifiers replicate the blockchain state, ensuring its availability and fault tolerance. Replication is managed by the consensus algorithm, which selects nodes (Proof of Replication) to maintain and share the state.
Validators:
Validators consume bandwidth from Verifiers and help in the consensus process. These virtual nodes can run on the same machines as the Verifiers or Leader, or on separate nodes specifically dedicated to the consensus.
Network Efficiency:
The Leader node processes incoming transactions and orders them in a way that maximizes memory access efficiency, reducing faults and improving prefetching. The system supports a minimum payload size, which involves destination accounts and transaction details (such as fees and amounts). The system can handle up to 710,000 transactions per second (TPS) under optimal network conditions, with redundancy strategies to increase availability.
Computational and Memory Limits:
Each transaction requires a digest verification, which can be parallelized. Computational throughput is limited by the number of cores available, with GPU-based servers capable of processing 900,000 operations per second. Memory-wise, the system can theoretically handle up to 10 billion accounts in 640GB of memory. Based on access patterns, the system can manage 2.75 million transactions per second.
High-Performance Smart Contracts:
The system also supports high-performance smart contracts, implemented using Berkeley Packet Filter (BPF) bytecode. BPF allows efficient execution and analysis of smart contracts, utilizing a zero-cost Foreign Function Interface (FFI). Smart contracts can invoke platform-level intrinsics, like ECDSA verification, which are batched and executed on GPUs for enhanced throughput.
This architecture emphasizes high scalability, fault tolerance, and performance through optimized transaction handling, smart contract execution, and advanced replication strategies.