

Introduction
What is Chubby?
It is like a distributed file system with advisory locks, with the design focussing on availability and reliability instead of performance
Chubby is intended for use within a loosely-coupled distributed system, consisting of moderately large number of machines connected by a high-speed network
The purpose of the lock service is to allow its clients to synchronise their activities and agree on basic information about their environment
The primary goals for chubby were
Availability
Reliability
Easy to understand semantics
Throughput and storage space were considered as secondary goals
The intent behind making chubby was to help devs deal with
coarse-grained synchronisationand to help elect a leader from a set of equivalent servers
🔑 What does coarse-grained synchronisation mean ?
Imagine you have a big toy box that you share with your sister. Coarse-grained synchronization is like making a rule: "Only one person can play with the toy box at a time."
When you want to play:
You put a sign on the toy box that says "Being used by [your name]"
You can then take out any toys you want
When you're done, you remove the sign
Your sister has to wait until you're completely finished and remove your sign before she can use the toy box. She can't grab toys while you're using it, even if she wants different toys than you're playing with.
This is simple but sometimes slow - like when your sister just wants one small toy while you're playing with completely different ones, she still has to wait for you to finish with the whole box.
GFS uses a Chubby lock to elect master server, Bigtable uses Chubby to elect master, allow master to see the servers it controls and permit clients to find the master
Both GFS and BigTable use Chubby to store small amounts of meta-data (i.e they use Chubby as root of their distributed data-structure)
Before Chubby :
Adhoc methods were used for master election for most distributed systems at Google
Chubby allowed for a small save in computation for this case
Operator intervention also became necessary (when correctness was important) at times
Using chubby high availability was obtained in systems that no longer required human intervention
One of the problems that chubby solves, primary election, is an instance of the distributed consensus problem, that requires a solution using asynchronous communication. One way to solve async consensus is Paxos protocol
🔑 TLDR on Paxos Protocol
Imagine a group of friends trying to order pizza over text messages, but:
Phone networks are spotty (messages might not arrive)
Some friends might fall asleep (stop responding)
You need most friends to agree on the order
Here's how Paxos would work:
PROPOSE: Alice texts "Let's get pepperoni? Anyone against this? Reply 1234"
The number 1234 is important - it's higher than any previous pizza proposals
PROMISE: Friends check if they've already promised to support another pizza choice with a higher number
If not, they reply "OK, I'll support pepperoni (1234)"
If they already promised to support something else with a higher number, they say "Can't, already promised 1235 for mushroom"
ACCEPT: If Alice gets "OK" from more than half the friends, she texts "It's decided - pepperoni (1234)"
Why this works:
Even if Bob fell asleep, enough friends agreed
Even if Carol didn't get the initial text, she'll eventually learn the decision
If David simultaneously proposed mushroom pizza with 1235, only one choice would get enough promises
In computers, this ensures all servers agree on data even when some fail or can't communicate briefly.
Design
Rationale
Imagine 2 ways of making computers work together properly
One is “Ask master” (centralised like chubby) the master clarifies everything and tells each computer what to do
The other is “democracy approach” (something similar to a library implementation for Paxos)
Both these approaches have their own pros and cons, simply putting it other words it's like the difference between:
Having to ask a teacher for permission to do anything
Giving students guidelines to make decisions as a group
A lock service (Chubby) has some advantages over a client library
Devs do not always plan for high availability, as the system grows availability becomes more and more important
A lock service makes it easier to maintain existing programming structure and comparison as opposed to a client library
🔑 to elect a master which then writes to an existing file server requires adding just two statements and one RPC parameter to an existing system
One would acquire a lock to become master, pass an additional integer (the lock acquisition count) with the write RPC, and add an if-statement to the file server to reject the write if the acquisition count is lower than the current value (to guard against delayed packets)
A lot of the services at google that elect a primary OR partition data between their components need a mechanism for advertising result
For this we need to allow clients to store and fetch small quantities of data
This could be done with a name service, but Google’s experience has been that the lock service itself is well-suited for this task, because this
reduces the number of servers on which a client depends,
and because the consistency features of the protocol are shared
A lock based interface is more familiar
Think of three different ways to make group decisions:
The Committee Way (Distributed-consensus):
Like having 5 people on a committee
Need at least 3 to agree to make any decision
Good because decisions are well-discussed
Bad because you need lots of people available
The Hall Monitor Way (Lock Service/Chubby):
One person gets the "hall pass" to make decisions
Only need one person to be active
The hall monitor is backed by a reliable team (like Chubby's 5 servers)
Simpler because one person can move things forward
The Voting Service Way (Consensus Service):
Like hiring a professional voting company to manage decisions
Also lets one person move forward with decisions
But if used for anything besides taking turns (locks), it doesn't solve other problems
Real-world example:
Committee Way: Like needing 3 out of 5 family members to agree on dinner
Hall Monitor Way: One person gets to pick, backed by parents who make sure it's fair
Voting Service: Asking a neighbor to manage your family decisions
The Hall Monitor Way (lock service) is often the best choice because:
It's simple - one person can make progress
It's still safe - backed by a reliable system
It solves more problems than just decision-making
The above discussed reasons led to 2 key design decisions
Chose a lock service as opposed to a library or service for consensus
Chose to serve small-files to allow primary (master) to advertise and make their parameters known instead of building and maintaining a second service
Some other key design decisions taken were
A service advertising its primary via a Chubby file may have thousands of clients. Therefore, we must allow thousands of clients to observe this file, preferably without needing many servers.
Clients and replicas of a replicated service may wish to know when the service’s primary changes.
This suggests that an event notification mechanism would be useful to avoid polling
Even if clients need not poll files periodically, many will (this is a consequence of supporting many developers).
Thus, caching of files is desirable. Google devs prefer consistent caching.
To provide security mechanisms, including access control.
A rather surprising choice is that the lock use is not expected to be fine grained on the contrary a coarse grained use is expected
🔑Fine-grained locks are a way to control access to small, specific pieces of data or resources in a system. Instead of restricting access to a large chunk of resources all at once, fine-grained locks allow for more precise control, letting multiple users or processes access different parts of the system simultaneously. This approach increases efficiency by minimizing unnecessary waiting, though it requires more complex management.
Difference in fine-grained and coarse grained locks
Coarse-grained locks (big, less frequent locks):
Don't stress the lock server much
If the lock server is briefly unavailable, it's not a big deal
Need to be reliable and not disappear if the server hiccups
Work well with fewer servers
Fine-grained locks (small, frequent locks):
Put more stress on the lock server
If the server is unavailable even briefly, many users get stuck
Don't need to survive server problems
Need more servers to handle all the requests
It's okay if these locks disappear sometimes since they're short-lived anyway
The key difference: Coarse-grained locks prioritize reliability, while fine-grained locks prioritize speed and handling many requests.
Chubby also lets clients implement their own fine grained locks, in short the scene is :
Chubby's Main Job
Only handles big, less frequent locks
Like controlling access to entire systems
Lets you add your own DIY Smaller Locks
Users can create their own system for smaller, frequent locks
They use Chubby's big locks to manage their small-lock system
Easy to Set Up
Small-lock servers are simple
They just need a counter that goes up
Don't need to save much information
Benefits
Users manage their own servers for small locks
Don't have to figure out the hard stuff about making computers agree
Can customize locks for their specific needs
System structure
Chubby has 2 main components that communicate via RPC. The components are
A server
A library that client applications link against
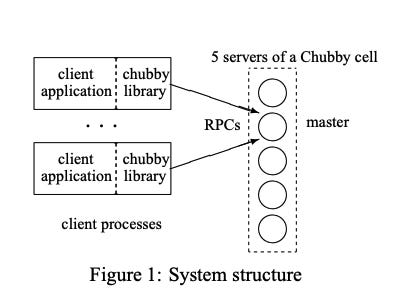
One chubby cell has 5 servers called replicas, these replicas reduce the likelihood of correlated failures.
The replicas use a distributed consensus protocol to elect a master
master must obtain votes from a majority of the replicas, plus promises that those replicas will not elect a different master for an interval of a few seconds known as the master lease
The master lease is continued if the same replica wins again
Replicas maintain a simple DB but only the master initiates reads and writes to this DB, all other replicas just copy data from the master
Clients find the master by sending master location requests to the replicas listed in the DNS.
Non-master replicas respond to such requests by returning the identity of the master.
The client then directs all requests to the master either until it ceases to respond, or until it indicates that it is no longer the master
Write requests are propagated via the consensus protocol to all replicas; such requests are acknowledged when the write has reached a majority of the replicas in the cell
Read requests are satisfied by the master alone
this is safe provided the master lease has not expired, as no other master can possibly exist.
if a master fails, the other replicas run the election protocol when their master leases expire;
a new master will typically be elected in a few seconds
If a replica fails and does not recover for a few hours, a new system is selected from the available pool, starts the lock server binary on it and updates the DNS with the new IP address
The current master server periodically checks the DNS and eventually notices changes, such as new replicas.
The master updates the list of members in the cell’s database, which is kept consistent across all members using the replication protocol.
The new replica gets a recent copy of the database from backups stored on file servers and updates from active replicas.
Once the new replica processes a request that the current master is waiting to commit, it becomes eligible to vote in the elections for a new master.
Files, directories and handles
Chubby has a similar but simpler file system interface than UNIX
A typical chubby file name is
/ls/foo/bar/abcThe ls prefix is common to all Chubby names and stands for
lock-servicethe second component
foois the name of the chubby cell, it is resolved to one or more chubby servers via DNS lookupA special cell name
localmeans that clients local chubby cell should be used
The remainder
/bar/abcin interpreted within the replica
Because the naming structure resembled a filesystem it was easier to be made available to apps using a simple API
The design is different from UNIX to ease distribution
To allow the files in different directories to be served from different Chubby masters, Chubby does not expose operations that can move files from one directory to another,
Chubby does not maintain directory modified times,
Chubby avoids path-dependent permission semantics
To make it easier to cache file meta-data, the system does not reveal last-access times.
The namespace has file and directories collectively called
nodesEvery such node has only one name within its cell
There are no symbolic or hard links
🔑A symbolic link is like a shortcut or pointer to another file or directory. A hard link is a direct reference to the data of a file.
Nodes may be permanent or ephemeral (short-lived)
Any node may be deleted explicitly, but ephemeral nodes are also deleted if no client has them open,
Ephemeral files are used as temporary files, and as indicators to others that a client is alive
Any node can act as an advisory reader/writer lock
Each node has some meta-data the most important one being 3 ACLs (Access control lists) for controlling read, write and updating ACL names for the node
By default, on creation, a node takes the ACL of its parent
ACLs are located in the ACL directory which is a know part in the cell’s local name space
Because Chubby’s ACLs are simply files, they are automatically available to other services that wish to use similar access control mechanisms.
Each node has a 4 monotonically increasing 64-bit numbers in its metadata
These numbers allow the client to detect changes easily
The 4 numbers are :
an instance number → greater than the instance number of any previous node with the same name.
a content generation number (files only) → this increases when the file’s contents are written.
a lock generation number → this increases when the node’s lock transitions from free to held.
an ACL generation number → this increases when the node’s ACL names are written
Chubby also exposes a 64-bit file-content checksum so clients may tell whether files differ
🔑A checksum is a small, fixed-size value (usually a number) generated from a larger set of data, like a file or message. It acts as a fingerprint of the data, allowing you to detect changes or errors.
When a client wants to check if a file has changed, instead of reading the entire file, it can simply compare the stored checksum with the current checksum. If the checksums differ, the file content has changed; if they are the same, the file content is identical*
When clients open a file or directory (called a node), they get something called a "handle," which works like a file descriptor in UNIX.
A handle lets the client interact with the file, similar to how file descriptors are used in UNIX to read, write, or manage files.
Each handle has "check digits," which act like a security feature.
These digits make it impossible for clients to create fake handles or guess valid ones.
This means full access checks only need to happen when the handle is created, not every time the client reads or writes data (unlike UNIX, where permissions are checked when the file is opened).
The handle also includes a sequence number.
This helps the master server know if the handle was created by it or a previous master (in case the master has been restarted).
When the handle is created, it stores mode information (like read-only or write permissions).
If the master restarts and an old handle is presented, the mode information helps the master remember how the handle should behave.
Locks and sequencers
Each Chubby file and directory can act as a reader-writer lock
One client handle may hold the lock in exclusive (writer) mode
Multiple clients hold the lock in shared (reader) mode
Locks are advisory, they conflict only with other attempts to acquire the same lock
Holding a lock is NOT necessary to access the file and it does NOT prevent other clients from doing so
Google chose to reject mandatory locks (client needs to have lock to access file) because :
Chubby locks often protect resources managed by other services, not just the file linked to the lock. Enforcing strict (mandatory) locking would require big changes to those services.
The team did not want to require users to shut down applications when they needed to access locked files for debugging or administrative purposes. In complex systems, it is not practical to shut down or reboot to bypass locks, as is commonly done on personal computers.
The developers perform error checking using standard methods like "assertions" (e.g., "lock X is held"). They see little benefit from mandatory lock checks, as faulty or malicious processes can still corrupt data even without holding locks.
Since data can be corrupted in other ways, the extra protection provided by mandatory locking is considered to add little value
In Chubby acquiring a lock in either read or write mode needs a write permission so that an unprivileged reader cannot prevent writer from making progress
Chubby provides a way by which sequence numbers can be introduced into only those interactions that make use of locks.
At any time, a lock holder may request a sequencer, an opaque byte-string that describes the state of the lock immediately after acquisition.
It contains the name of the lock, the mode in which it was acquired (exclusive or shared), and the lock generation number.
Clients gives this sequencer to servers IF it expects the operation to be protected by the lock
Recipient server tests if the sequencer is still valid and has the correct mode, if it doesn’t the request is rejected
The validity of the sequencer can be checked with the help of the Chubby server’s cache or with the help of the most recent sequencer that the server has observed
while sequencers (a system for keeping requests in order) are effective and simple to use, important protocols (rules that govern communication between systems) tend to evolve slowly, which can lead to delays or issues with request ordering.
Since not all systems or servers support sequencers, Chubby provides an alternative mechanism that, while not perfect, is easier to use and helps reduce the chances of:
Delayed requests (when requests arrive too late).
Re-ordered requests (when requests are processed out of order).
If client gives away the lock in a normal way then lock is made available immediately for other clients, but if the client looses the lock due to failure then lock waits for a period called
lock-delayThis limit prevents a faulty client from making a lock unavailable for a long time
This protects unmodified servers and clients from everyday problems caused by message delays and restarts
🔑In short , the lock-delay prevents new clients from immediately grabbing a lock when the previous client fails, reducing the risk of inconsistency or conflicts from delayed messages or sudden restarts of the original client. This protects servers that aren’t designed to handle such timing issues.
Events
The clients may subscribe to various number of events when creating the handle.
The events are delivered to the client async via an up-call from Chubby library
Events include :
modified content inside files
child node changed (added, removed or modified)
master failed over
handle failed or has become invalid
lock acquired
conflicting lock req from another client
Events are delivered AFTER the action has occurred
API
Handles are created with
Open()and destroyed withClose()Open()opens a named file or directory to produce a handle.Only this call takes a node name, all other operations use handles
The client indicates various options :
how the handle will be used (reading; writing and locking; changing the ACL). The handle is created only if the client has the appropriate permissions.
events that should be delivered .
the lock-delay.
whether a new file or directory should (or must) be created. If a file is created, the caller may supply initial contents and initial ACL names. The return value indicates whether the file was in fact created.
Close()closes an open handle and further use of this handle is not allowedThis call NEVER fails
A similar call
Poison()causes outstanding and subsequent operations on the handle to fail without closing the handleThis allows a client to cancel Chubby calls made by other threads without fear of deallocating the memory being accessed by them.
Some important APIs are covered below :
Reading Files
GetContentsAndStat(): The Swiss Army knife of reads
Grabs both file content and metadata
Always reads the ENTIRE file
No partial reads allowed (Chubby's way of saying "keep your files small!")
GetStat(): The lightweight alternative
Just fetches metadata
Perfect when you don't need the actual content
ReadDir(): The directory explorer
Lists all children in a directory
Includes metadata for each child
Writing Files
SetContents(): The all-or-nothing writer
Writes complete files atomically
Optional bonus: Compare-and-swap with generation numbers
If generation = current:
Update file
Else:
Sorry, try again!
File Management
SetACL(): The bouncer
Updates Access Control Lists
Decides who gets in and who doesn't
Delete(): The cautious cleaner
Deletes nodes
But only if they have no children
Chubby's version of "Are you sure you want to delete this?"
Lock Operations:
Acquire(): The classic lock grabber
TryAcquire(): The "no-wait" alternative
Release(): The lock liberator
Sequencer Operations:
GetSequencer(): Gets your "proof of lock" token
SetSequencer(): Binds a sequencer to your handle
CheckSequencer(): Validates if a sequencer is still legit
Handle Behavior:
Handles are tied to file instances, not names
If a file is deleted and recreated, old handles won't work
Every call can face access control checks
Open() calls ALWAYS face the security check
All API calls include an operation parameter for:
Async callbacks
Waiting for completion
Getting detailed error info
File handles become invalid if:
The file is deleted
Even if a new file is created with the same name
Here's how servers use Chubby to elect a leader:
All potential primaries:
Open the lock file
Try to acquire the lock
The winner:
Becomes the primary
Writes its identity to the lock file
Gets a sequencer as proof
Other servers:
Read the file to find the primary
Can verify the primary's sequencer
Safety feature:
Lock-delay mechanism for services that can't check sequencers
Sessions and KeepAlives
Think of a Chubby session as a "relationship status" between a client and a Chubby cell. It's like:
A virtual handshake 🤝
Has an expiration date
Needs regular check-ins to stay alive
Working of a session :
Starting Up
Client says "Hey, let's connect!"
Master says "Ok macha, here's your session!"
Staying Alive
Client sends "KeepAlive" messages
Like saying "Alive?" every now and then
Master responds with "Got it, enjoy for another 12 seconds!"
If the master is busy, it might say "You're good for longer" to reduce check-ins
Failure scenarios
Jeopardy Mode
Client thinks "Uh oh, haven't heard from the master in a while..."
Empties its cache (better safe than sorry!)
Starts a 45-second countdown (called the "grace period")
What Happens Next?
If they reconnect: Everything goes back to normal
If time runs out: Session is considered dead ⚰️
🔑Think of it like a video call:
If the connection gets bad, you might say "Can you hear me?" (jeopardy mode)
You wait a bit to see if it improves (grace period)
If it doesn't get better, you hang up and redial (session expires)
Fail-overs
When a master fails or looses its status as master it looses all of its in-memory state
until a new master is elected the session lease timer is stopped
this is legal because it is equivalent to extending the client’s lease.
If new master election happens before local lease expiry, clients can contact the new master and things continue
Else all the clients flush their caches and wait for grace period to find new master
the grace period allows sessions to be maintained across fail-overs that exceed the normal lease timeout.
Example Scenario
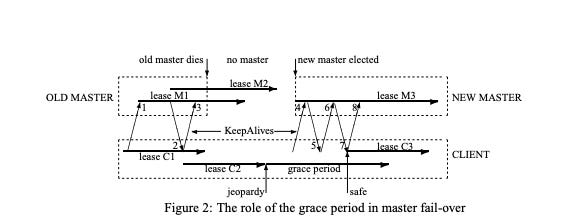
OLD MASTER has lease M1
OLD MASTER exchanges KeepAlives with CLIENT
OLD MASTER extends to lease M2
OLD MASTER sends lease M2 info in KeepAlive reply #2
CLIENT updates its view to lease C2 (shorter than master's lease)
OLD MASTER suddenly dies
OLD MASTER had already committed to lease M2
CLIENT sends a KeepAlive
No response received by CLIENT
Time passes with no master available
CLIENT's lease C2 expires
CLIENT enters "jeopardy" mode:
Empties its cache
Initiates grace period timer
Continuously attempts to locate new master
NEW MASTER is elected
NEW MASTER initializes with lease M3
Takes cautious approach about previous leases
CLIENT attempts KeepAlive #4
This attempt is rejected due to incorrect epoch number
CLIENT makes another attempt with KeepAlive #6
This second attempt succeeds
NEW MASTER sends KeepAlive reply #7
CLIENT extends to new lease C3
If grace period bridges gap between C2 and C3:
CLIENT only experiences a delay
No session failure is detected
CLIENT exits "jeopardy" mode
Normal operations resume
Conclusions
Grace period is crucial for maintaining sessions during fail-over
System handles master changes without losing client sessions
Multiple attempts may be needed to establish connection with new master
Epoch numbers prevent confusion between old and new masters
The newly elected master proceeds to the following immediately after election
It assigns a fresh "epoch number" to clients. If a client uses an old epoch number, its requests are rejected. This prevents the new master from responding to outdated requests sent to a previous master.
The new master can now respond to requests asking for its location but doesn't yet handle session-related operations.
The master rebuilds in-memory data for sessions and locks using the information stored in the database. It extends session leases to match what the previous master may have used.
Clients can now send "KeepAlives" (signals that they’re still active), but they can't perform other session-related actions yet.
The master sends a fail-over event to each session, prompting clients to clear their caches (since they may have missed updates) and warn applications that some events might have been lost.
The master waits for clients to acknowledge the fail-over event or lets their sessions expire if they don't respond.
Once acknowledgements are received, the master allows all operations to continue as normal.
If a client uses a handle created before the fail-over, the master rebuilds the handle’s information and processes the request. Once a handle is closed, it cannot be recreated in the current epoch to avoid accidental duplication from delayed or repeated messages.
After a short period, the master deletes temporary (ephemeral) files that no longer have active handles. However, if a client loses its session during the fail-over, the file may not disappear right away.
Database implementation
The first version of Chubby used Berkeley DB as its database, which stores data using a system called B-trees.
A special function was used to sort data based on the structure of file paths, keeping related files close together.
Chubby didn’t need path-based permissions, so only one lookup was needed to access a file in the database.
Berkeley DB uses a distributed consensus protocol to share its data logs across multiple servers, which fit well with Chubby’s system once master leases were added.
While the B-tree part of Berkeley DB was reliable, the newer replication system wasn’t as well-tested and had fewer users.
Even though the Berkeley DB team fixed issues, Chubby’s developers thought using the replication feature was risky.
To reduce this risk, the team created a simpler database using write-ahead logging and snapshotting, similar to another design.
They continued to share the database logs across servers using a distributed consensus protocol.
Chubby didn’t use many of Berkeley DB’s features, so creating a simpler system made everything easier to manage.
They needed atomic operations (simple all-or-nothing tasks), but didn’t require more complex transactions.
Mirroring
Chubby allows files to be mirrored (copied) from one cell to another.
Mirroring is fast because the files are small, and Chubby’s event system instantly informs when a file is added, deleted, or changed.
If the network is working properly, changes are mirrored globally in less than a second.
If a mirror can't be reached due to network issues, it stays unchanged until the connection is restored. The updated files are identified by comparing their checksums.
Mirroring is mainly used to copy configuration files to different computing clusters worldwide.
A special cell called global contains a folder that is mirrored to the corresponding folder in every other Chubby cell.
The global cell is special because its replicas are spread across the world, ensuring it's almost always accessible.
Files mirrored from the global cell include:
Chubby's access control lists (ACLs)
Files for monitoring services that track the presence of Chubby cells and other systems
Links to help clients find large datasets like Bigtable cells
Many configuration files for other systems.
That’s it for most of the technical concepts and understanding for Chubby let us now try and understand how Google tried to scale it
Mechanism for scaling
Chubby clients are individual processes, so the system often handles more clients than expected,
sometimes up to 90,000 clients 🤯 communicating with a single Chubby master.
Since each Chubby cell only has one master and the master machine is similar to client machines, the master can get overwhelmed if too many clients communicate with it at once.
The best way to scale Chubby is by reducing communication with the master, as small improvements in request processing won’t make much of a difference.
Several strategies are used to manage this load:
Chubby can have multiple cells, and clients usually connect to a nearby one (found through DNS) to avoid relying on remote machines. A typical deployment uses one cell for a data center with several thousand machines.
The master can increase lease times (from the default 12 seconds to up to 60 seconds) under heavy load to reduce the number of KeepAlive requests it needs to process.
Chubby clients cache file data, metadata, file absence, and open handles to reduce the number of requests they make to the server.
Protocol-conversion servers are used to convert the Chubby protocol into simpler ones like DNS, reducing complexity.
Two additional methods, proxies and partitioning, are designed to further improve scaling, although they are not yet in production.
Chubby doesn't need to scale beyond a factor of five for now because:
There's a limit to how many machines one would put in a data center or rely on a single service.
Hardware improvements will increase the capacity of both clients and servers, so they will grow together.
Proxies
Chubby’s protocol can be proxied by trusted processes that forward requests from clients to a Chubby cell.
Proxies can reduce server load by handling KeepAlive and read requests, but they can't reduce write traffic since writes bypass the proxy’s cache.
Even though write traffic isn't reduced, it makes up less than 1% of Chubby's workload, so proxies can still greatly increase the number of clients supported.
A proxy that manages N clients reduces KeepAlive traffic by a factor of N, which can be 10,000 or more.
A proxy cache can reduce read traffic by up to a factor of 10, but since reads are less than 10% of the load, the savings from reduced KeepAlive traffic are more significant.
Proxies add extra RPCs to write operations and first-time reads.
While proxies may cause the system to become unavailable more often (since each proxied client depends on both the proxy and the Chubby master), the overall benefits in scaling outweigh the risks.
Partitioning
The system can divide a Chubby cell into N partitions, where each partition has its own set of replicas and a master.
The partition for a directory or node is determined by a hash function.
Every node
D/Cin directoryDwould be stored on the partitionP(D/C) = hash(D) mod NMetadata maybe stored in a different partition
Some operations, like ACL checks and ensuring directories are empty before deletion, may require cross-partition communication.
However, these cases are limited, and the performance impact is expected to be modest.
Partitioning reduces read and write traffic on each partition by a factor of N, but it doesn't necessarily lower KeepAlive traffic.
Proxies and partitioning together are considered the solution for scaling Chubby to handle more clients.
Resources
While I didn’t get the chance to spend a lot of time with this paper, here are some resources that helped me understand some of the concepts discussed in this paper
A lecture on the paper :
The Whitepaper :
https://static.googleusercontent.com/media/research.google.com/en//archive/chubby-osdi06.pdf
Paxos algorithm :
really liked this post. do you folks also do little implementations of these systems, if yes would be interested to pitch in too,